재무 보고서 검색 시스템 구축

재무 보고서는 회사의 건강을 평가하는 데 중요합니다. 수백 페이지에 걸쳐 특정 통찰력을 효율적으로 추출하기가 어렵습니다. 애널리스트와 투자자는 대차 대조표, 소득 진술 및 각주를 통해 체로 체례하는 데 시간을 소비하여 -와 같은 간단한 질문에 대답합니다. 2024 년 회사의 수익은 얼마입니까? LLM 모델 및 벡터 검색 기술의 최근 발전으로 Llamaindex 및 관련 프레임 워크를 사용하여 재무 보고서 분석을 자동화 할 수 있습니다. 이 블로그 게시물은 Llamaindex, Chromadb, Gemini2.0 및 Ollama를 사용하여 정밀한 보고서의 쿼리에 대한 쿼리에 대한 강력한 금융 래그 시스템을 구축하는 방법을 탐구합니다.
학습 목표
- 효율적인 분석을 위해 재무 보고서 검색 시스템의 필요성을 이해하십시오.
- llamaindex를 사용하여 재무 보고서를 전제 및 벡터화하는 방법을 알아보십시오.
- 문서 검색을위한 강력한 벡터 데이터베이스를 구축하려면 ChromADB를 탐색하십시오.
- 재무 데이터 분석을 위해 Gemini 2.0 및 LLAMA 3.2를 사용하여 쿼리 엔진을 구현하십시오.
- 강화 된 통찰력을 위해 llamaindex를 사용하여 고급 쿼리 라우팅 기술을 발견하십시오.
이 기사는의 일부로 출판되었습니다 데이터 과학 블로그.
재무 보고서 검색 시스템이 필요한 이유는 무엇입니까?
재무 보고서에는 수익, 비용, 부채 및 수익성을 포함한 회사의 성과에 대한 중요한 통찰력이 포함되어 있습니다. 그러나이 보고서는 크고 길고 기술적 인 전문 용어로 가득 차있어 분석가, 투자자 및 경영진이 관련 정보를 수동으로 추출 할 수 있도록 매우 시간이 많이 걸립니다.
재무 보고서 검색 시스템은 자연어 쿼리를 활성화 하여이 프로세스를 자동화 할 수 있습니다. PDF를 검색하는 대신 사용자는 단순히 다음과 같은 질문을 할 수 있습니다.2023 년의 수익은 얼마입니까?” 또는 “2023 년의 유동성 문제를 요약하십시오.”시스템은 관련 섹션을 신속하게 검색하고 요약하여 수동 노력의 시간을 절약합니다.
프로젝트 구현
프로젝트 구현을 위해서는 먼저 환경을 설정하고 필요한 라이브러리를 설치해야합니다.
1 단계 : 환경 설정
우리는 개발 작업을 위해 만들어지고 콘다를 시작할 것입니다.
$conda create --name finrag python=3.12
$conda activate finrag2 단계 : 필수 파이썬 라이브러리를 설치하십시오
LibraRaires 설치는 모든 프로젝트 구현의 중요한 단계입니다.
$pip install llama-index llama-index-vector-stores-chroma chromadb
$pip install llama-index-llms-gemini llama-index-llms-ollama
$pip install llama-index-embeddings-gemini llama-index-embeddings-ollama
$pip install python-dotenv nest-asyncio pypdf3 단계 : 프로젝트 디렉토리 작성
이제 프로젝트 디렉토리를 만들고 .env라는 파일을 만들고 해당 파일에 모든 API 키를 보안 API 키 관리를 위해 넣으십시오.
# on .env file
GOOGLE_API_KEY="" 민감한 API 키를 안전하게 저장하기 위해 .env 파일에서 환경 변수를로드합니다. 이를 통해 Gemini API 또는 Google API가 보호되지 않도록합니다.
Jupyter Notebook을 사용하여 프로젝트를 수행 할 것입니다.
Jupyter 노트북 파일을 만들고 단계별로 구현을 시작하십시오.
4 단계 : API 키로드
이제 아래에 API 키를로드합니다.
import os
from dotenv import load_dotenv
load_dotenv()
GEMINI_API_KEY = os.getenv("GOOGLE_API_KEY")
# Only to check .env is accessing properly or not.
# print(f"GEMINI_API_KEY: {GEMINI_API_KEY}")이제 우리의 환경이 준비되어 다음 가장 중요한 단계로 갈 수 있습니다.
llamaindex로 처리하는 문서
연례 보고서 웹 사이트에서 Motorsport Games Inc. 재무 보고서 수집.
여기에서 링크를 다운로드하십시오.
첫 페이지는 다음과 같습니다.
이 보고서에는 총 123 페이지가 있지만 보고서의 재무 제표를 작성하고 프로젝트를위한 새로운 PDF를 만듭니다.
어떻게해야하나요? PYPDF 라이브러리는 매우 쉽습니다.
from pypdf import PdfReader
from pypdf import PdfWriter
reader = PdfReader("NASDAQ_MSGM_2023.pdf")
writer = PdfWriter()
# page 66 to 104 have financial statements.
page_to_extract = range(66, 104)
for page_num in page_to_extract:
writer.add_page(reader.pages[page_num])
output_pdf = "Motorsport_Games_Financial_report.pdf"
with open(output_pdf, "wb") as outfile:
writer.write(output_pdf)
print(f"New PDF created: {output_pdf}")새 보고서 파일에는 38 페이지 만 있으므로 문서를 신속하게 포함시키는 데 도움이됩니다.
재무 보고서로드 및 분할
프로젝트 데이터 디렉토리에 새로 생성 된 Motorsport_Games_Financial_Report.pdf 파일을 넣습니다.
재무 보고서는 일반적으로 광범위한 테이블 데이터, 각주 및 법적 진술을 포함하는 PDF 형식입니다. Llamaindex의 SimpledirectoryReader를 사용하여 이러한 문서를로드하여 문서로 변환합니다.
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()보고서는 단일 문서로 처리하기에 매우 크기 때문에 작은 청크 또는 노드로 슬립니다. 각 청크는 페이지 나 섹션에 해당하며보다 효율적으로 검색하는 데 도움이됩니다.
from copy import deepcopy
from llama_index.core.schema import TextNode
def get_page_nodes(docs, separator="\n---\n"):
"""Split each document into page node, by separator."""
nodes = []
for doc in docs:
doc_chunks = doc.text.split(separator)
for doc_chunk in doc_chunks:
node = TextNode(
text=doc_chunk,
metadata=deepcopy(doc.metadata),
)
nodes.append(node)
return nodes문서 수집 과정을 이해하려면 아래 다이어그램을 참조하십시오.
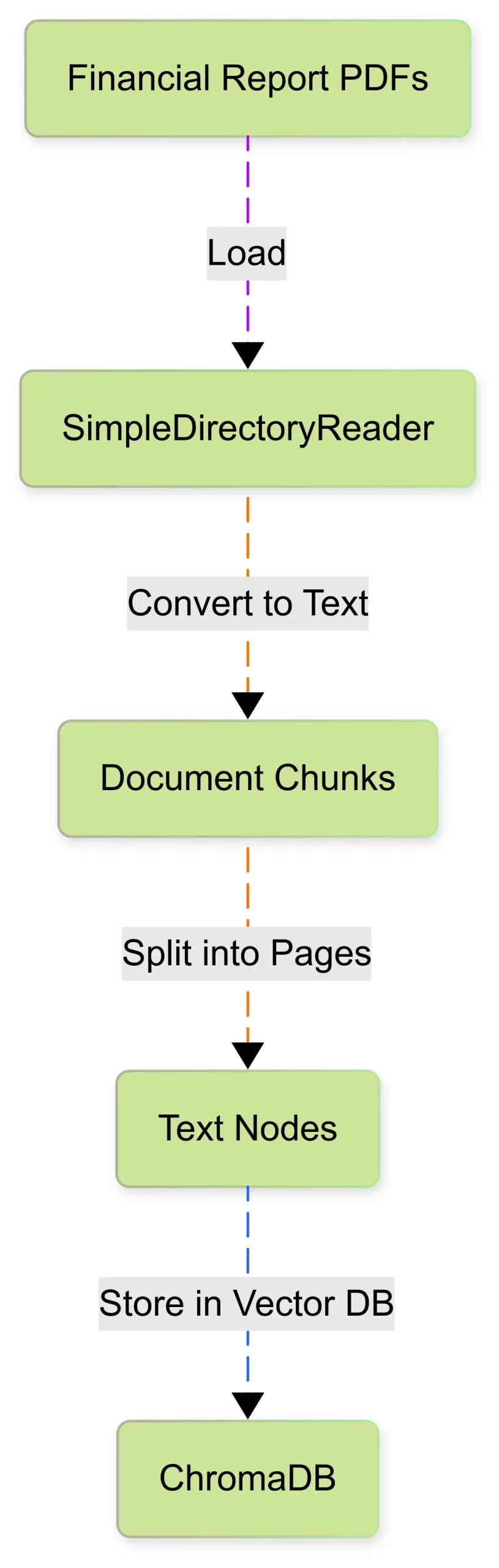
이제 우리의 재무 데이터는 검색을위한 벡터화 및 저장 준비가되었습니다.
ChromADB로 벡터 데이터베이스 구축
빠르고 정확하며 로컬 벡터 데이터베이스에 ChromADB를 사용합니다. 재무 텍스트의 임베디드 표현은 ChromADB에 저장됩니다.
벡터 데이터베이스를 초기화하고 로컬 임베딩 생성을 위해 Ollama를 사용하여 Nomic-embed-Text 모델을 구성합니다.
import chromadb
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import Settings
embed_model = OllamaEmbedding(model_name="nomic-embed-text")
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("financial_collection")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)마지막으로 Llamaindex의 VectorStoreIndex를 사용하여 벡터 인덱스를 만듭니다. 이 인덱스는 벡터 데이터베이스를 Llamaindex의 쿼리 엔진에 연결합니다.
from llama_index.core import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
vector_index = VectorStoreIndex.from_documents(documents=documents, storage_context=storage_context, embed_model=embed_model)위의 코드는 금융 텍스트 문서에서 Nomic-embed-Text를 사용하여 벡터 인덱스를 생성합니다. 로컬 시스템 사양에 따라 시간이 걸립니다.
인덱싱이 완료되면 다시 인덱싱하지 않고 필요할 때 내장 된 재사용 코드를 사용할 수 있습니다.
vector_index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, embed_model=embed_model
)이렇게하면 스토리지에서 ChromADB 포함 파일을 사용할 수 있습니다.
이제 우리의 무거운 로딩이 완료되었고, 보고서를 쿼리하고 휴식을 취할 시간입니다.
Gemini 2.0을 통한 쿼리 재무 데이터
재무 데이터가 색인화되면 자연어 질문을하고 정확한 답변을받을 수 있습니다. 쿼리를 위해 벡터 데이터베이스와 상호 작용하는 gemini-2.0 플래시 모델을 사용하여 관련 섹션을 가져오고 통찰력 응답을 생성합니다.
Gemini-2.0 설정
from llama_index.llms.gemini import Gemini
llm = Gemini(api_key=GEMINI_API_KEY, model_name="models/gemini-2.0-flash")
벡터 인덱스와 함께 Gemini 2.0을 사용하여 쿼리 엔진을 시작하십시오
query_engine = vector_index.as_query_engine(llm=llm, similarity_top_k=5)엑사쿼리 및 응답
아래에는 응답이 다른 여러 쿼리가 있습니다.
쿼리 -1
response = query_engine.query("what is the revenue of on 2022 Year Ended December 31?")
print(str(response))응답

보고서에서 해당 이미지 :

쿼리 -2
response = query_engine.query(
"what is the Net Loss Attributable to Motossport Games Inc. on 2022 Year Ended December 31?"
)
print(str(response))응답

보고서에서 해당 이미지 :
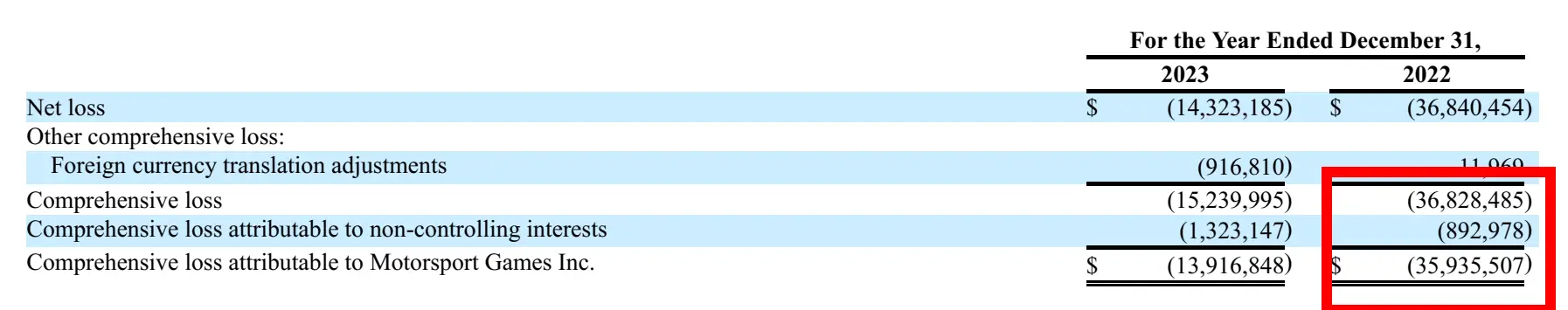
쿼리 -3
response = query_engine.query(
"What are the Liquidity and Going concern for the Company on December 31, 2023"
)
print(str(response))응답

쿼리 -4
response = query_engine.query(
"Summarise the Principal versus agent considerations of the company?"
)
print(str(response))응답

보고서의 상관 이미지 :

쿼리 -5
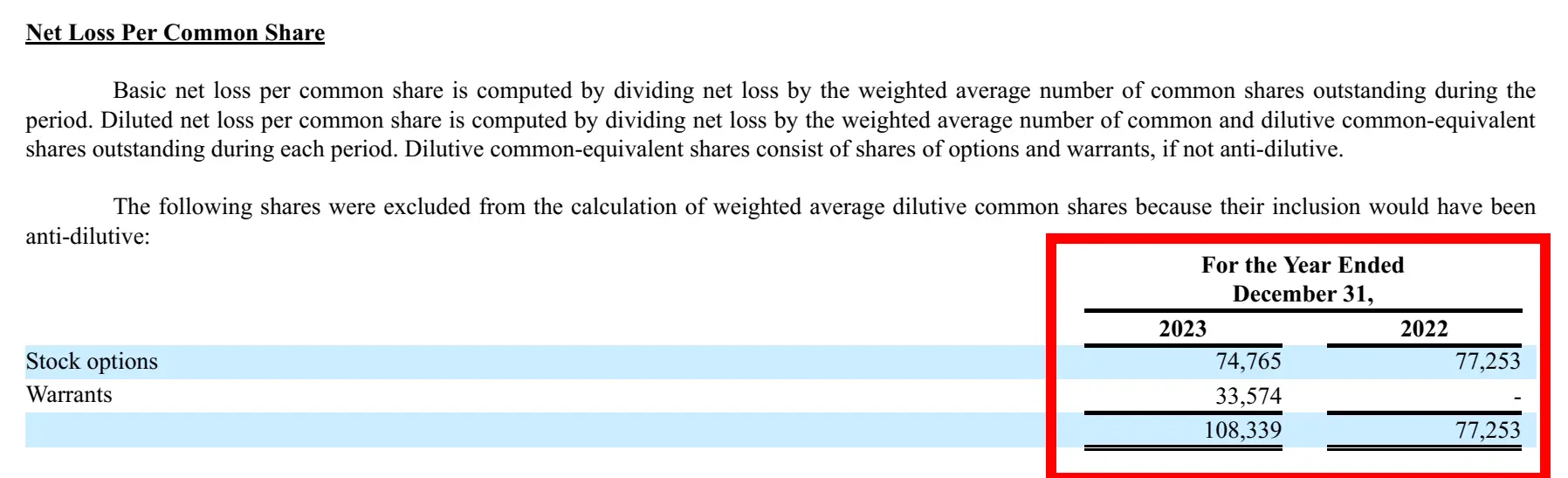
response = query_engine.query(
"Summarise the Net Loss Per Common Share of the company with financial data?"
)
print(str(response))응답

보고서의 상관 이미지 :
쿼리 -6
response = query_engine.query(
"Summarise Property and equipment consist of the following balances as of December 31, 2023 and 2022 of the company with financial data?"
)
print(str(response))응답

보고서에서 해당 이미지 :

쿼리 -7
response = query_engine.query(
"Summarise The Intangible Assets on December 21, 2023 of the company with financial data?"
)
print(str(response))응답

쿼리 -8
response = query_engine.query(
"What are leases of the company with yearwise financial data?"
)
print(str(response))응답
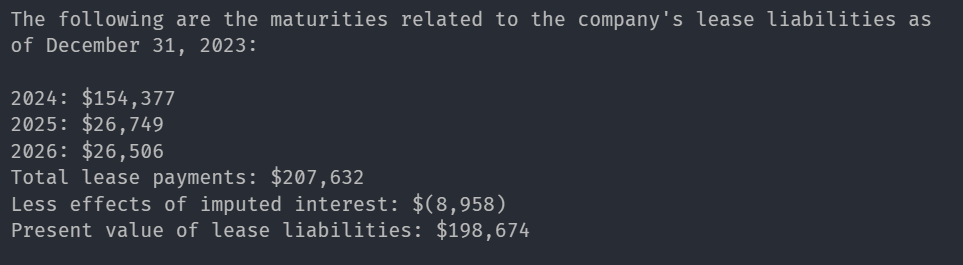
보고서에서 해당 이미지 :

llama 3.2를 사용한 로컬 쿼리
클라우드 기반 모델에 의존하지 않고 재무 보고서를 쿼리하기 위해 LLAMA 3.2를 레버리지하십시오.
라마 3.2 : 1b
local_llm = Ollama(model="llama3.2:1b", request_timeout=1000.0)
local_query_engine = vector_index.as_query_engine(llm=local_llm, similarity_top_k=3)쿼리 -9
response = local_query_engine.query(
"Summary of chart of Accrued expenses and other liabilities using the financial data of the company"
)
print(str(response))응답
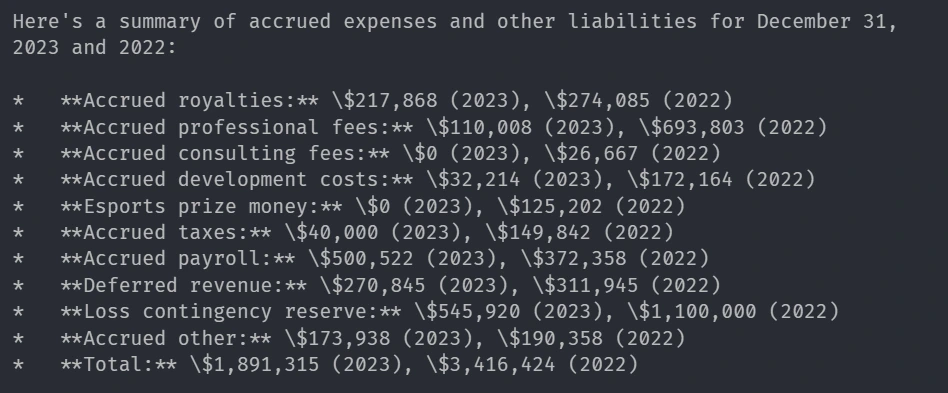
보고서의 상관 이미지 :
llamaindex를 사용한 고급 쿼리 라우팅
때로는 상세한 검색 및 요약 된 통찰력이 모두 필요합니다. 벡터 인덱스와 요약 지수를 모두 결합하여이를 수행 할 수 있습니다.
- 정확한 문서 검색을위한 벡터 인덱스
- 간결한 재무 요약에 대한 요약 색인
우리는 이미 벡터 인덱스를 구축했으며 이제는 재무 제표 요약을위한 계층 적 접근법을 사용하는 요약 색인을 만들 것입니다.
from llama_index.core import SummaryIndex
summary_index = SummaryIndex(nodes=page_nodes)그런 다음 쿼리 유형을 기반으로 요약 색인 또는 벡터 인덱스에서 데이터를 검색할지 여부를 조건부로 결정하는 RouterQueryEngine을 통합합니다.
from llama_index.core.tools import QueryEngineTool
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector이제 요약 쿼리 엔진을 작성합니다
summary_query_engine = summary_index.as_query_engine(
llm=llm, response_mode="tree_summarize", use_async=True
)이 요약 쿼리 엔진은 요약 도구로 들어갑니다. 벡터 쿼리 엔진을 벡터 도구에 넣습니다.
# Creating summary tool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to Motorsport Games Company."
),
)
# Creating vector tool
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=(
"Useful for retriving specific context from the Motorsport Games Company."
),
)두 도구는 이제 라우터를 통해 이러한 도구를 연결하여 라우터를 통해 쿼리 엉덩이를 사용하면 사용자 쿼리를 분석하여 사용할 도구를 결정할 수 있습니다.
# Router Query Engine
adv_query_engine = RouterQueryEngine(
llm=llm,
selector=LLMSingleSelector.from_defaults(llm=llm),
query_engine_tools=[summary_tool, vector_tool],
verbose=True,
)고급 쿼리 시스템은 완전히 설정되어 새로 선호하는 고급 쿼리 엔진을 쿼리합니다.
쿼리 -10
response = adv_query_engine.query(
"Summarize the charts describing the revenure of the company."
)
print(str(response))응답

쿼리 사용자가 요약을 요구하기 때문에 Intelligent Router가 요약 도구를 사용하기로 결정할 것임을 알 수 있습니다.
쿼리 -11
response = adv_query_engine.query("What is the Total Assets of the company Yearwise?")
print(str(response))응답
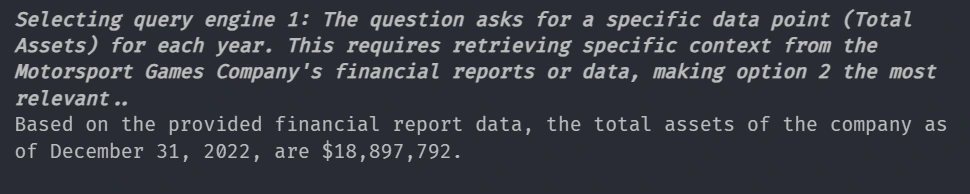
그리고 여기에서 라우터는 사용자가 요약이 아닌 특정 정보를 요구하기 때문에 벡터 도구를 선택합니다.
이 기사에 사용 된 모든 코드는 여기에 있습니다
결론
Llamaindex, ChromADB 및 Advanced LLM으로 재무 보고서를 효율적으로 분석 할 수 있습니다. 이 시스템을 사용하면 자동화 된 재무 통찰력, 실시간 쿼리 및 강력한 요약이 가능합니다. 이러한 유형의 시스템은 금융 분석을보다 접근 가능하고 효율적으로 투자, 거래 및 비즈니스 수행 중에 더 나은 결정을 내릴 수 있도록합니다.
주요 테이크 아웃
- LLM 전동 문서 검색 시스템은 복잡한 재무 보고서 분석에 소요되는 시간을 크게 줄일 수 있습니다.
- 클라우드 및 로컬 LLM을 사용한 하이브리드 접근 방식은 비용 효율적이고 개인 정보 및 유연한 시스템을 설계하는 방법을 보장합니다.
- llamaindex의 모듈 식 프레임 워크
- 이 유형의 시스템은 법률 문서, 의료 보고서 및 규제 제출과 같은 다양한 영역에 적응할 수있어 다목적 래그 솔루션이됩니다.
자주 묻는 질문
A.이 시스템은 구조화 된 재무 문서를 텍스트 청크로 나누고 포함하여 ChromADB에 저장하여 처리하도록 설계되었습니다. 완전한 재 인덱싱없이 새로운 보고서를 동적으로 추가 할 수 있습니다.
A. 예, Matplotlib, Pandas 및 Streamlit을 통합하면 매출 성장, 순 손실 분석 또는 자산 분배와 같은 추세를 시각화 할 수 있습니다.
A. RouterqueryEngine은 쿼리에 요약 된 응답 또는 특정 재무 데이터 검색이 필요한지 자동으로 감지합니다. 이는 관련없는 출력을 줄이고 응답의 정밀도를 보장합니다.
A. 가능하지만 벡터 스토어가 얼마나 자주 업데이트되는지에 따라 다릅니다. 실시간 재무 보고서 쿼리를 위해 연속 섭취 파이프 라인에 OpenAI Imbedding API를 사용할 수 있습니다.
이 기사에 표시된 미디어는 분석 Vidhya가 소유하지 않으며 저자의 재량에 따라 사용됩니다.
![]()
자기 가르치고 프로젝트 중심의 학습자 인 딥 러닝, 컴퓨터 비전 및 NLP에 관한 복잡한 프로젝트 작업을 좋아합니다. 나는 항상 딥 러닝, 머신 러닝 또는 물리와 같은 분야에있을 수있는 주제에 대해 깊은 이해를 얻으려고 노력합니다. 내 학습에 대한 콘텐츠를 만드는 것을 좋아합니다. 내 이해를 세상과 나누십시오.
계속해서 읽고 전문가가 구축 된 콘텐츠를 즐기십시오.












: 아우라 카버부터 아우라 잉크까지")
Post Comment