제품 성분 분석을 위한 다중 모드 에이전트 구축
제품의 성분 목록을 쳐다보며 익숙하지 않은 화학 이름을 검색하여 그 의미를 알아낸 적이 있습니까? 이는 일반적인 어려움입니다. 즉석에서 복잡한 제품 정보를 해독하는 것은 부담스럽고 시간 소모적일 수 있습니다. 각 성분을 개별적으로 검색하는 것과 같은 전통적인 방법은 종종 단편적이고 혼란스러운 결과로 이어집니다. 하지만 제품 성분을 분석하고 명확하고 실행 가능한 통찰력을 즉시 얻을 수 있는 더 스마트하고 빠른 방법이 있다면 어떨까요? 이 기사에서는 Gemini 2.0, Phidata 및 Tavily Web Search를 사용하여 제품 성분 분석기를 구축하는 과정을 안내합니다. 그 성분 목록을 한 번에 살펴보고 이해해 봅시다!
학습 목표
- 비전 언어 작업을 위해 Phidata 및 Gemini 2.0을 사용하여 다중 모드 AI 에이전트 아키텍처를 설계합니다.
- 더 나은 컨텍스트 및 정보 검색을 위해 Tavily Web Search를 에이전트 워크플로에 통합합니다.
- 자세한 제품 통찰력을 위해 이미지 처리와 웹 검색을 결합하는 제품 성분 분석기 에이전트를 구축하세요.
- 다중 모드 작업에서 시스템 프롬프트와 지침이 상담원 행동을 어떻게 안내하는지 알아보세요.
- 실시간 이미지 분석, 영양 정보 및 건강 기반 제안을 위한 Streamlit UI를 개발합니다.
이 기사는 의 일환으로 게재되었습니다. 데이터 과학 블로그톤.
다중 모드 시스템이란 무엇입니까?
다중 모드 시스템은 텍스트, 이미지, 오디오, 비디오 등 여러 유형의 입력 데이터를 동시에 처리하고 이해합니다. Gemini 2.0 Flash, GPT-4o, Claude Sonnet 3.5 및 Pixtral-12B와 같은 비전 언어 모델은 이러한 양식 간의 관계를 이해하고 복잡한 입력에서 의미 있는 통찰력을 추출하는 데 탁월합니다.
이러한 맥락에서 우리는 이미지를 분석하고 텍스트 통찰력을 생성하는 비전 언어 모델에 중점을 둡니다. 이러한 시스템은 컴퓨터 비전과 자연어 처리를 결합하여 사용자 프롬프트에 따라 시각적 정보를 해석합니다.
다중 모드 실제 사용 사례
다중 모드 시스템은 산업을 변화시키고 있습니다.
- 재원: 사용자는 온라인 양식에서 익숙하지 않은 용어를 스크린샷으로 찍고 즉시 설명을 들을 수 있습니다.
- 전자상거래: 쇼핑객은 제품 라벨을 사진으로 촬영하여 자세한 성분 분석과 건강 인사이트를 얻을 수 있습니다.
- 교육: 학생들은 교과서 도표를 캡처하고 간단한 설명을 들을 수 있습니다.
- 헬스케어: 환자는 의료 보고서나 처방전 라벨을 스캔하여 용어 및 복용량 지침에 대한 간단한 설명을 확인할 수 있습니다.
왜 다중 모드 에이전트인가?
단일 모드 AI에서 다중 모드 에이전트로의 전환은 AI 시스템과 상호 작용하는 방식에 있어 큰 도약을 의미합니다. 다중 모드 에이전트를 효과적으로 만드는 이유는 다음과 같습니다.
- 시각적 정보와 텍스트 정보를 동시에 처리하여 보다 정확하고 상황에 맞는 응답을 제공합니다.
- 복잡한 정보를 단순화하여 기술 용어나 자세한 콘텐츠로 어려움을 겪는 사용자가 액세스할 수 있도록 합니다.
- 개별 구성 요소를 수동으로 검색하는 대신 사용자는 이미지를 업로드하고 한 단계로 포괄적인 분석을 받을 수 있습니다.
- 웹 검색 및 이미지 분석과 같은 도구를 결합하여 보다 완전하고 신뢰할 수 있는 통찰력을 제공합니다.
건축자재 성분 분석 에이전트
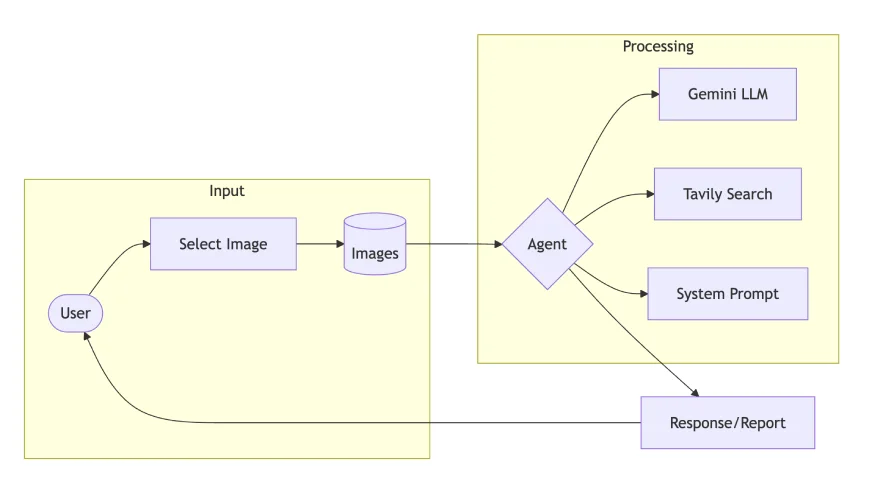
제품 성분 분석 에이전트의 구현을 분석해 보겠습니다.
1단계: 종속성 설정
- Gemini 2.0 플래시: 향상된 비전 기능으로 다중 모드 처리 처리
- Tavily Search: 추가 컨텍스트를 위한 웹 검색 통합 제공
- Phidata: 에이전트 시스템을 조정하고 워크플로를 관리합니다.
- Streamlit: 프로토타입을 웹 기반 애플리케이션으로 개발합니다.
!pip install phidata google-generativeai tavily-python streamlit pillow2단계: API 설정 및 구성
이 단계에서는 환경 변수를 설정하고 이 사용 사례를 실행하는 데 필요한 API 자격 증명을 수집합니다.
from phi.agent import Agent
from phi.model.google import Gemini # needs a api key
from phi.tools.tavily import TavilyTools # also needs a api key
import os
TAVILY_API_KEY = ""
GOOGLE_API_KEY = ""
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEY
os.environ['GOOGLE_API_KEY'] = GOOGLE_API_KEY 3단계: 시스템 프롬프트 및 지침
언어 모델로부터 더 나은 응답을 얻으려면 더 나은 프롬프트를 작성해야 합니다. 여기에는 역할을 명확하게 정의하고 LLM에 대한 시스템 프롬프트에 자세한 지침을 제공하는 것이 포함됩니다.
성분 분석 및 영양에 대한 전문 지식을 갖춘 에이전트의 역할과 책임을 정의해 보겠습니다. 지침은 대리인이 식품을 체계적으로 분석하고, 성분을 평가하고, 식이 제한을 고려하고, 건강에 미치는 영향을 평가하도록 안내해야 합니다.
SYSTEM_PROMPT = """
You are an expert Food Product Analyst specialized in ingredient analysis and nutrition science.
Your role is to analyze product ingredients, provide health insights, and identify potential concerns by combining ingredient analysis with scientific research.
You utilize your nutritional knowledge and research works to provide evidence-based insights, making complex ingredient information accessible and actionable for users.
Return your response in Markdown format.
"""
INSTRUCTIONS = """
* Read ingredient list from product image
* Remember the user may not be educated about the product, break it down in simple words like explaining to 10 year kid
* Identify artificial additives and preservatives
* Check against major dietary restrictions (vegan, halal, kosher). Include this in response.
* Rate nutritional value on scale of 1-5
* Highlight key health implications or concerns
* Suggest healthier alternatives if needed
* Provide brief evidence-based recommendations
* Use Search tool for getting context
"""4단계: 에이전트 개체 정의
Phidata를 사용하여 구축된 에이전트는 마크다운 형식을 처리하고 앞서 정의한 시스템 프롬프트 및 지침에 따라 작동하도록 구성됩니다. 이번 예시에 사용된 추론 모델은 Gemini 2.0 Flash로, 다른 모델에 비해 이미지와 영상을 이해하는 능력이 뛰어난 것으로 알려져 있습니다.
도구 통합을 위해 우리는 불필요한 설명, URL 및 관련 없는 매개변수를 피하면서 사용자 쿼리에 직접 응답하여 관련 컨텍스트를 제공하는 고급 웹 검색 엔진인 Tavily Search를 사용할 것입니다.
agent = Agent(
model = Gemini(id="gemini-2.0-flash-exp"),
tools = [TavilyTools()],
markdown=True,
system_prompt = SYSTEM_PROMPT,
instructions = INSTRUCTIONS
)5단계: 다중 모드 – 이미지 이해
이제 에이전트 구성요소가 준비되었으므로 다음 단계는 사용자 입력을 제공하는 것입니다. 이는 두 가지 방법으로 수행할 수 있습니다. 즉, 제공된 이미지에서 추출해야 하는 정보를 지정하는 사용자 프롬프트와 함께 이미지 경로 또는 URL을 전달하는 것입니다.
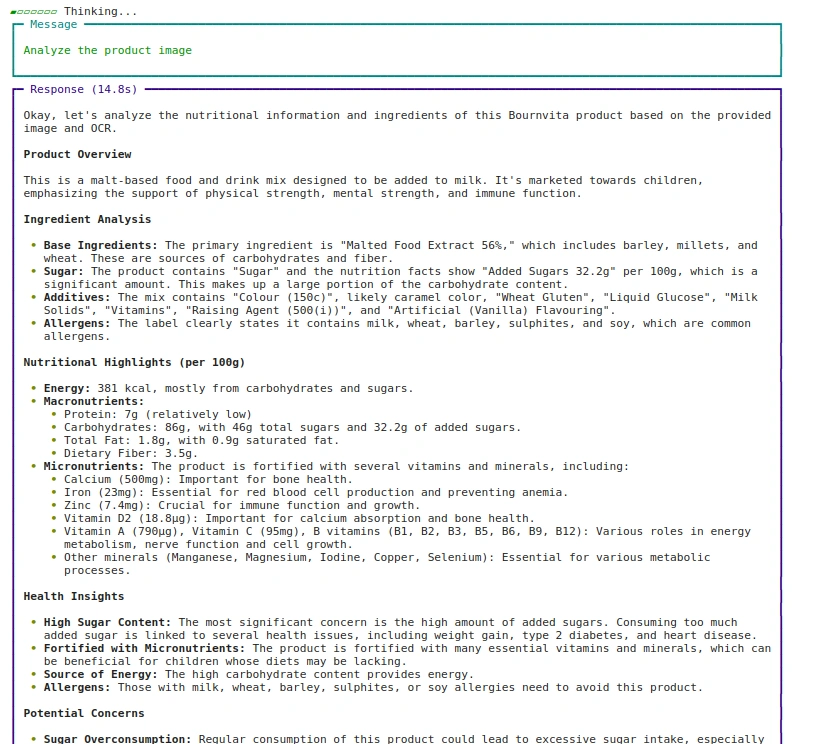
접근법: 1 이미지 경로 사용

agent.print_response(
"Analyze the product image",
images = ["images/bournvita.jpg"],
stream=True
)산출:
접근법: 2 URL 사용
agent.print_response( "제품 이미지 분석", 이미지 = ["
stream=True
)Output:
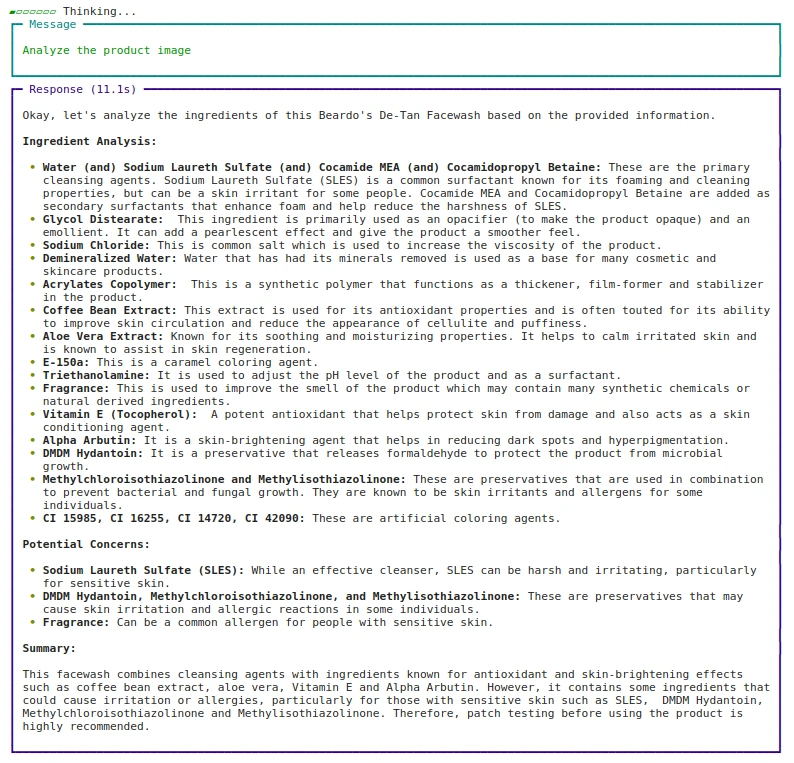
Step 6: Develop the Web App using Streamlit
Now that we know how to execute the Multimodal Agent, let’s build the UI part using Streamlit.
import streamlit as st
from PIL import Image
from io import BytesIO
from tempfile import NamedTemporaryFile
st.title("🔍 Product Ingredient Analyzer")To optimize performance, define the Agent inference under a cached function. The cache decorator helps improve efficiency by reusing the Agent instance.
Since we are using Streamlit, which refreshes the entire page after each event loop or widget trigger, adding st.cache_resource ensures the function is not refreshed and saves it in the cache.
@st.cache_resource
def get_agent():
return Agent(
model=Gemini(id="gemini-2.0-flash-exp"),
system_prompt=SYSTEM_PROMPT,
instructions=INSTRUCTIONS,
tools=[TavilyTools(api_key=os.getenv("TAVILY_API_KEY"))]마크다운=True, )사용자가 새로운 이미지 경로를 제공하면 analyze_image 함수가 실행되어 get_agent에 정의된 Agent 개체를 실행합니다. 실시간 캡처 및 이미지 업로드 옵션의 경우, 처리를 위해 업로드된 파일을 임시로 저장해야 합니다.
이미지는 임시 파일에 저장되며, 실행이 완료되면 리소스 확보를 위해 임시 파일을 삭제합니다. 이는 임시 파일 라이브러리의 NamedTemporaryFile 함수를 사용하여 수행할 수 있습니다.
def analyze_image(image_path):
agent = get_agent()
with st.spinner('Analyzing image...'):
response = agent.run(
"Analyze the given image",
images=[image_path],
)
st.markdown(response.content)
def save_uploaded_file(uploaded_file):
with NamedTemporaryFile(dir=".", suffix='.jpg', delete=False) as f:
f.write(uploaded_file.getbuffer())
return f.name더 나은 사용자 인터페이스를 위해 사용자가 이미지를 선택할 때 해상도와 크기가 다양할 수 있습니다. 일관된 레이아웃을 유지하고 이미지를 적절하게 표시하기 위해 업로드되거나 캡처된 이미지의 크기를 조정하여 화면에 명확하게 맞도록 할 수 있습니다.
LANCZOS 리샘플링 알고리즘은 고품질 크기 조정을 제공하며, 특히 성분 분석에 텍스트 선명도가 중요한 제품 이미지에 유용합니다.
MAX_IMAGE_WIDTH = 300
def resize_image_for_display(image_file):
img = Image.open(image_file)
aspect_ratio = img.height / img.width
new_height = int(MAX_IMAGE_WIDTH * aspect_ratio)
img = img.resize((MAX_IMAGE_WIDTH, new_height), Image.Resampling.LANCZOS)
buf = BytesIO()
img.save(buf, format="PNG")
return buf.getvalue()7단계: Streamlit의 UI 기능
인터페이스는 사용자가 관심 분야를 선택할 수 있는 세 가지 탐색 탭으로 구분됩니다.
- 탭-1: 예시 제품 사용자가 앱을 테스트하기 위해 선택할 수 있는 항목
- 탭-2: 이미지 업로드 이미 저장되어 있는 경우 원하는 대로 선택하세요.
- Tab-3: 캡처 또는 라이브 사진 찍기 그리고 제품을 분석해보세요.
3개 탭 모두에 대해 동일한 논리적 흐름을 반복합니다.
- 먼저 원하는 이미지를 선택하고 다음을 사용하여 Streamlit UI에 표시되도록 크기를 조정합니다. st.이미지.
- 둘째, 해당 이미지를 임시 디렉터리에 저장하여 에이전트 개체로 처리합니다.
- 셋째, Gemini 2.0 LLM과 Tavily Search 도구를 이용하여 Agent가 실행될 이미지를 분석합니다.
상태 관리는 Streamlit의 세션 상태를 통해 처리되며 선택된 예제와 분석 상태를 추적합니다.

def main():
if 'selected_example' not in st.session_state:
st.session_state.selected_example = None
if 'analyze_clicked' not in st.session_state:
st.session_state.analyze_clicked = False
tab_examples, tab_upload, tab_camera = st.tabs([
"📚 Example Products",
"📤 Upload Image",
"📸 Take Photo"
])
with tab_examples:
example_images = {
"🥤 Energy Drink": "images/bournvita.jpg",
"🥔 Potato Chips": "images/lays.jpg",
"🧴 Shampoo": "images/shampoo.jpg"
}
cols = st.columns(3)
for idx, (name, path) in enumerate(example_images.items()):
with cols[idx]:
if st.button(name, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Upload product image",
type=["jpg", "jpeg", "png"],
help="Upload a clear image of the product's ingredient list"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.image(resized_image, caption="Uploaded Image", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Uploaded Image", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take a picture of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.image(resized_image, caption="Captured Photo", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Captured Photo", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Selected Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.image(resized_image, caption="Selected Example", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Example", key="analyze_example") and not st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)중요한 링크
- 여기에서 전체 코드를 찾을 수 있습니다.
- “를 교체하십시오.
” 자리 표시자를 키와 함께 입력하세요. - tab_examples의 경우 폴더 이미지가 필요합니다. 그리고 거기에 이미지를 저장하세요. 여기에 이미지 디렉터리가 포함된 GitHub URL이 있습니다.
- 사용 사례 사용에 관심이 있다면 여기에 배포된 앱이 있습니다.
결론
멀티모달 AI 에이전트는 일상 생활에서 복잡한 정보와 상호 작용하고 이해할 수 있는 방법에 있어 더 큰 도약을 의미합니다. 제품 성분 분석기와 같은 이러한 시스템은 비전 처리, 자연어 이해 및 웹 검색 기능을 결합하여 제품 및 해당 성분에 대한 즉각적이고 포괄적인 분석을 제공하여 모든 사람이 정보에 입각한 의사 결정에 보다 쉽게 접근할 수 있도록 해줍니다.
주요 시사점
- 다중 모드 AI 에이전트는 제품 정보를 이해하는 방법을 개선합니다. 텍스트와 이미지 분석을 결합합니다.
- 오픈 소스 프레임워크인 Phidata를 사용하면 에이전트 시스템을 구축하고 관리할 수 있습니다. 이 시스템은 GPT-4o 및 Gemini 2.0과 같은 모델을 사용합니다.
- 에이전트는 비전 처리 및 웹 검색과 같은 도구를 사용합니다. 이를 통해 분석이 더욱 완전하고 정확해집니다. LLM은 지식이 제한되어 있으므로 상담원은 도구를 사용하여 복잡한 작업을 더 잘 처리합니다.
- Streamlit을 사용하면 LLM 기반 도구용 웹 앱을 쉽게 구축할 수 있습니다. 예로는 RAG 및 다중 모드 에이전트가 있습니다.
- 좋은 시스템 메시지와 지침이 상담원을 안내합니다. 이는 유용하고 정확한 응답을 보장합니다.
자주 묻는 질문
A. LLaVA(Large Language and Vision Assistant), Mistral.AI의 Pixtral-12B, OpenFlamingo의 Multimodal-GPT, Nvidia의 NVILA 및 Qwen 모델은 작업을 위해 텍스트와 이미지를 처리하는 몇 가지 오픈 소스 또는 가중치 다중 모드 비전 언어 모델입니다. 시각적인 질문 답변처럼 말이죠.
A. 예, Llama 3은 다중 모드이며 Llama 3.2 Vision 모델(11B 및 90B 매개변수)은 텍스트와 이미지를 모두 처리하여 이미지 캡션 작성 및 시각적 추론과 같은 작업을 가능하게 합니다.
A. 다중 모드 대형 언어 모델(LLM)은 텍스트, 이미지, 오디오 등 다양한 형식에 걸쳐 데이터를 처리하고 생성합니다. 이와 대조적으로 다중 모드 에이전트는 이러한 모델을 활용하여 환경과 상호 작용하고, 작업을 수행하고, 다중 모드 입력을 기반으로 결정을 내리며, 종종 추가 도구와 시스템을 통합하여 복잡한 작업을 실행합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
![]()
AI Planet의 데이터 과학자 || YouTube- AIWithTarun || ML 분야 Google 개발자 전문가 || AI 해커톤 5회 우승 || TensorFlow 사용자 그룹 Bangalore의 공동 주최자 || DeepLearningAI의 파이 및 AI 홍보대사












Post Comment