예산에 맞춰 언어 모델 호스팅


편집자 이미지
# 소개
ChatGPT, 클로드, 쌍둥이자리. 당신은 이름을 알고 있습니다. 하지만 질문이 있습니다. 대신 자신만의 모델을 실행하면 어떻게 될까요? 야심찬 것처럼 들립니다. 그렇지 않습니다. 작업을 배포할 수 있습니다. 대규모 언어 모델 (LLM)을 1달러도 지출하지 않고 10분 이내에 완료할 수 있습니다.
이 기사에서는 이를 분석합니다. 먼저 실제로 필요한 것이 무엇인지 알아 보겠습니다. 그럼 실제 비용을 살펴보겠습니다. 마지막으로 Hugging Face에 TinyLlama를 무료로 배포하겠습니다.
모델을 출시하기 전에 아마도 마음속에 많은 질문이 있을 것입니다. 예를 들어, 내 모델이 수행할 작업은 무엇입니까?
이 질문에 답해 봅시다. 사용자 50명을 위한 봇이 필요한 경우 GPT-5는 필요하지 않습니다. 또는 하루에 1,200개 이상의 트윗에 대한 감정 분석을 수행할 계획이라면 500억 개의 매개변수가 있는 모델이 필요하지 않을 수도 있습니다.
먼저 몇 가지 널리 사용되는 사용 사례와 이러한 작업을 수행할 수 있는 모델을 살펴보겠습니다.
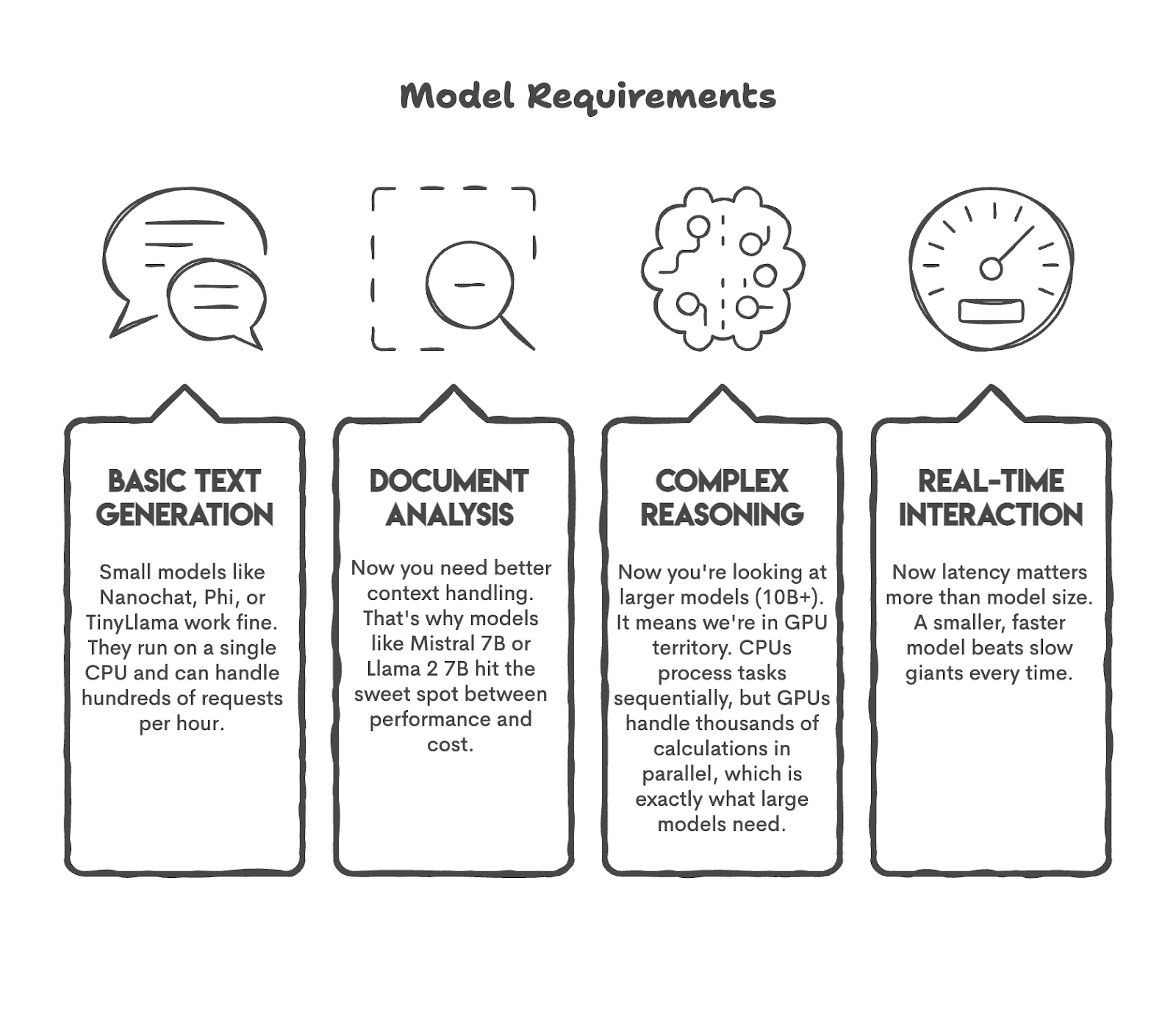
보시다시피 우리는 모델을 작업에 연결했습니다. 이것이 시작하기 전에 해야 할 일입니다.
# LLM 호스팅의 실제 비용 분석
이제 무엇이 필요한지 알았으니 비용이 얼마나 되는지 보여드리겠습니다. 모델 호스팅은 단지 모델에 관한 것이 아닙니다. 또한 이 모델이 실행되는 위치, 실행 빈도 및 상호 작용하는 사람의 수에 관한 것입니다. 실제 비용을 해독해 보겠습니다.
// 컴퓨팅: 직면하게 될 최대 비용
당신이 실행하는 경우 중앙처리장치 (CPU) 연중무휴 아마존 웹 서비스 (AWS) EC2의 경우 월 36달러 정도의 비용이 듭니다. 그러나 다음을 실행하면 그래픽 처리 장치 (GPU) 인스턴스의 경우 월 비용은 약 380달러로 비용의 10배 이상입니다. 따라서 대규모 언어 모델의 비용을 계산할 때는 주의해야 합니다. 이것이 주요 비용이기 때문입니다.
(계산은 대략적인 것입니다. 실제 가격을 보려면 여기에서 확인하십시오. AWS EC2 가격).
// 스토리지: 모델이 대규모가 아닌 한 적은 비용
디스크 공간을 대략적으로 계산해 보겠습니다. 7B(70억 매개변수) 모델은 약 14시간이 소요됩니다. 기가바이트 (GB). 클라우드 스토리지 비용은 매월 GB당 약 \$0.023입니다. 따라서 1GB 모델과 14GB 모델의 차이는 월 약 \$0.30에 불과합니다. 300B 매개변수 모델을 호스팅할 계획이 없다면 스토리지 비용은 무시할 수 있습니다.
// 대역폭: 확장할 때까지 저렴함
데이터가 이동할 때 대역폭이 중요하며, 다른 사람이 귀하의 모델을 사용할 때 데이터가 이동합니다. AWS는 첫 번째 GB 이후에는 GB당 \$0.09를 청구하므로 아주 저렴합니다. 그러나 수백만 개의 요청으로 확장하는 경우에도 이를 신중하게 계산해야 합니다.
(계산은 대략적인 것입니다. 실제 가격을 보려면 여기에서 확인하십시오. AWS 데이터 전송 가격).
// 지금 사용할 수 있는 무료 호스팅 옵션
포옹하는 얼굴 공간 CPU를 사용하여 소규모 모델을 무료로 호스팅할 수 있습니다. 세우다 그리고 철도 트래픽이 적은 데모에 적합한 무료 계층을 제공합니다. 개념 증명을 실험하거나 구축하는 경우에는 한 푼도 지출하지 않고도 상당한 성과를 거둘 수 있습니다.
# 실제로 실행할 수 있는 모델 선택
이제 비용을 알았습니다. 그렇다면 어떤 모델을 실행해야 할까요? 물론 각 모델에는 장점과 단점이 있습니다. 예를 들어, 1000억 개의 매개변수 모델을 노트북에 다운로드하는 경우 특별히 제작된 최고 수준의 워크스테이션이 없으면 작동하지 않을 것이라고 장담합니다.
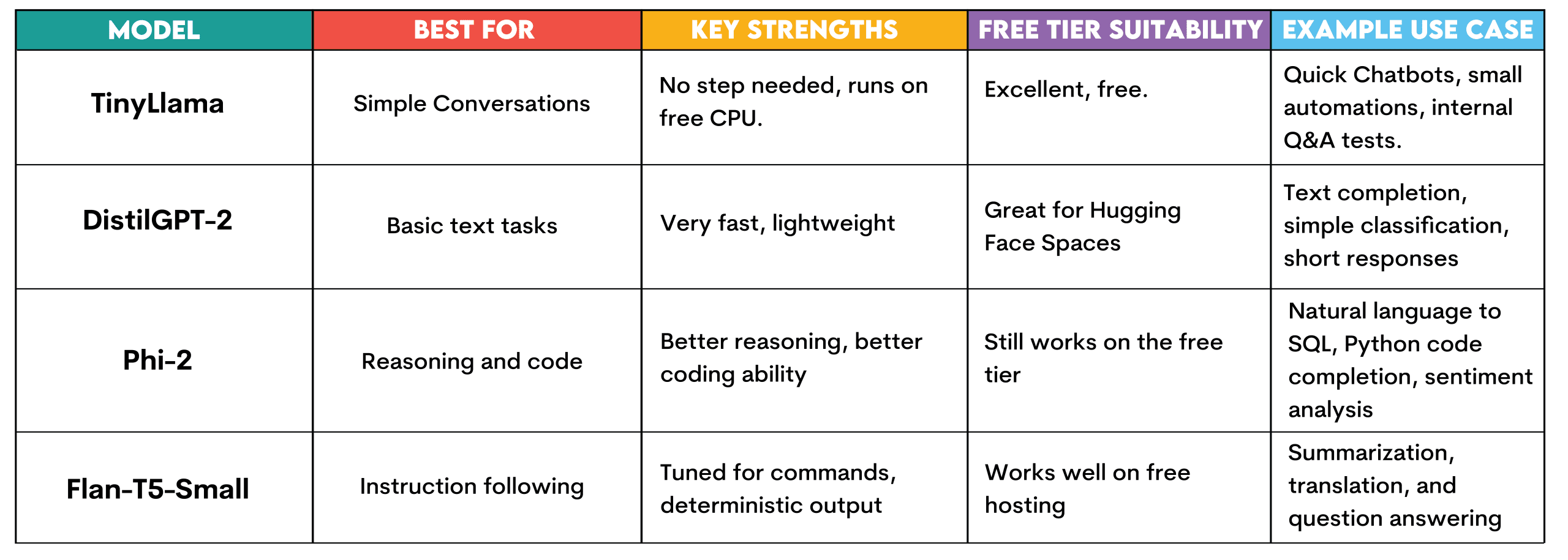
다음 섹션에서 설명할 것처럼 무료로 실행할 수 있도록 Hugging Face에서 사용할 수 있는 다양한 모델을 살펴보겠습니다.
작은라마: 이 모델은 설정이 필요하지 않으며 Hugging Face의 무료 CPU 계층을 사용하여 실행됩니다. 간단한 대화 작업, 간단한 질문에 대한 답변 및 텍스트 생성을 위해 설계되었습니다.
인프라 투자로 확장하기 전에 빠르게 구축하고 챗봇을 테스트하고, 빠른 자동화 실험을 실행하거나, 테스트용 내부 질문 답변 시스템을 만드는 데 사용할 수 있습니다.
증류GPT-2: 속도도 빠르고 가볍습니다. 이는 허깅 페이스 스페이스(Hugging Face Spaces)에 적합합니다. 텍스트 작성, 매우 간단한 분류 작업 또는 짧은 응답에 적합합니다. 리소스 제약 없이 LLM이 어떻게 작동하는지 이해하는 데 적합합니다.
파이-2: Microsoft에서 개발한 작은 모델로 매우 효과적입니다. Hugging Face의 무료 계층에서 계속 실행되지만 향상된 추론 및 코드 생성을 제공합니다. 자연어-SQL 쿼리 생성, 간단한 Python 코드 완성 또는 고객 리뷰 감정 분석에 사용하세요.
Flan-T5-소형: 이것은 Google의 지침 조정 모델입니다. 명령에 응답하고 답변을 제공하기 위해 만들어졌습니다. 요약, 번역, 질문 답변 등 무료 호스팅에서 결정적인 출력을 원하는 경우 생성에 유용합니다.
# 5분 안에 TinyLlama 배포
Hugging Face Spaces를 무료로 사용하여 TinyLlama를 구축하고 배포해 보겠습니다. 신용카드도, AWS 계정도, Docker 문제도 없습니다. 링크를 통해 공유할 수 있는 작동하는 챗봇입니다.
// 1단계: 포옹 얼굴 공간으로 이동
향하다 Huggingface.co/spaces 아래 스크린샷처럼 “새 공간”을 클릭하세요.
원하는 대로 공간 이름을 지정하고 간단한 설명을 추가하세요.
다른 설정은 그대로 둘 수 있습니다.
‘공간 만들기’를 클릭하세요.
// 2단계: app.py 작성
이제 아래 화면에서 “app.py 만들기”를 클릭하세요.
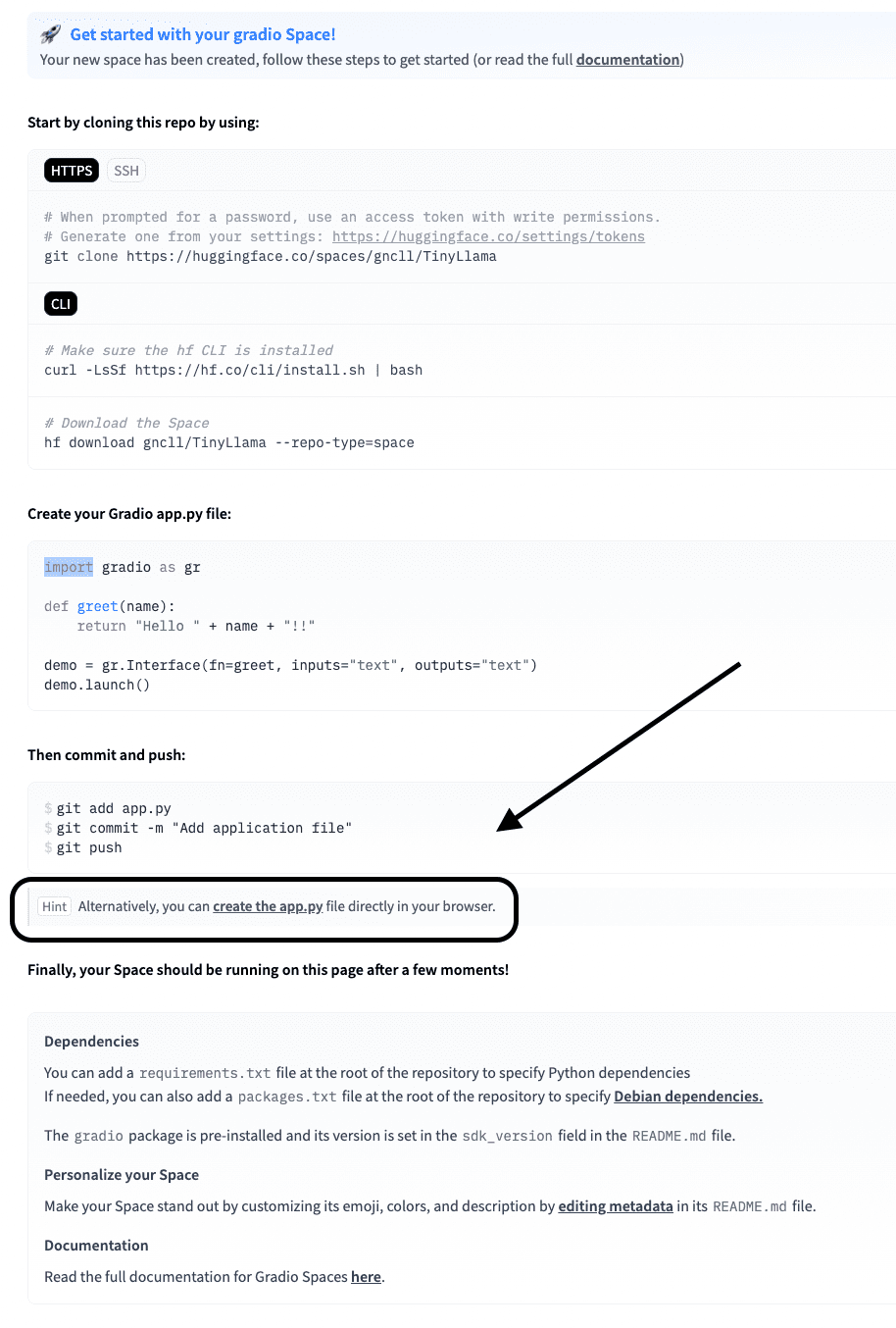
app.py 안에 아래 코드를 붙여넣으세요.
이 코드는 TinyLlama(Hugging Face에서 사용 가능한 빌드 파일 포함)를 로드하고 이를 채팅 기능으로 래핑한 다음 다음을 사용합니다. 세워짐 웹 인터페이스를 생성합니다. 그만큼 chat() 메소드는 메시지 형식을 올바르게 지정하고, 응답(최대 100개 토큰)을 생성하고, 질문한 질문에 대한 모델의 응답(반복은 포함하지 않음)만 반환합니다.
여기 Hugging Face 모델에 대한 코드 작성 방법을 배울 수 있는 페이지입니다.
코드를 보자.
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
def chat(message, history):
# Prepare the prompt in Chat format
prompt = f"\n{message}\n\n"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
return response
demo = gr.ChatInterface(chat)
demo.launch()코드를 붙여넣은 후 “새 파일을 메인에 커밋”을 클릭하세요. 예시로 아래 스크린샷을 확인해주세요.
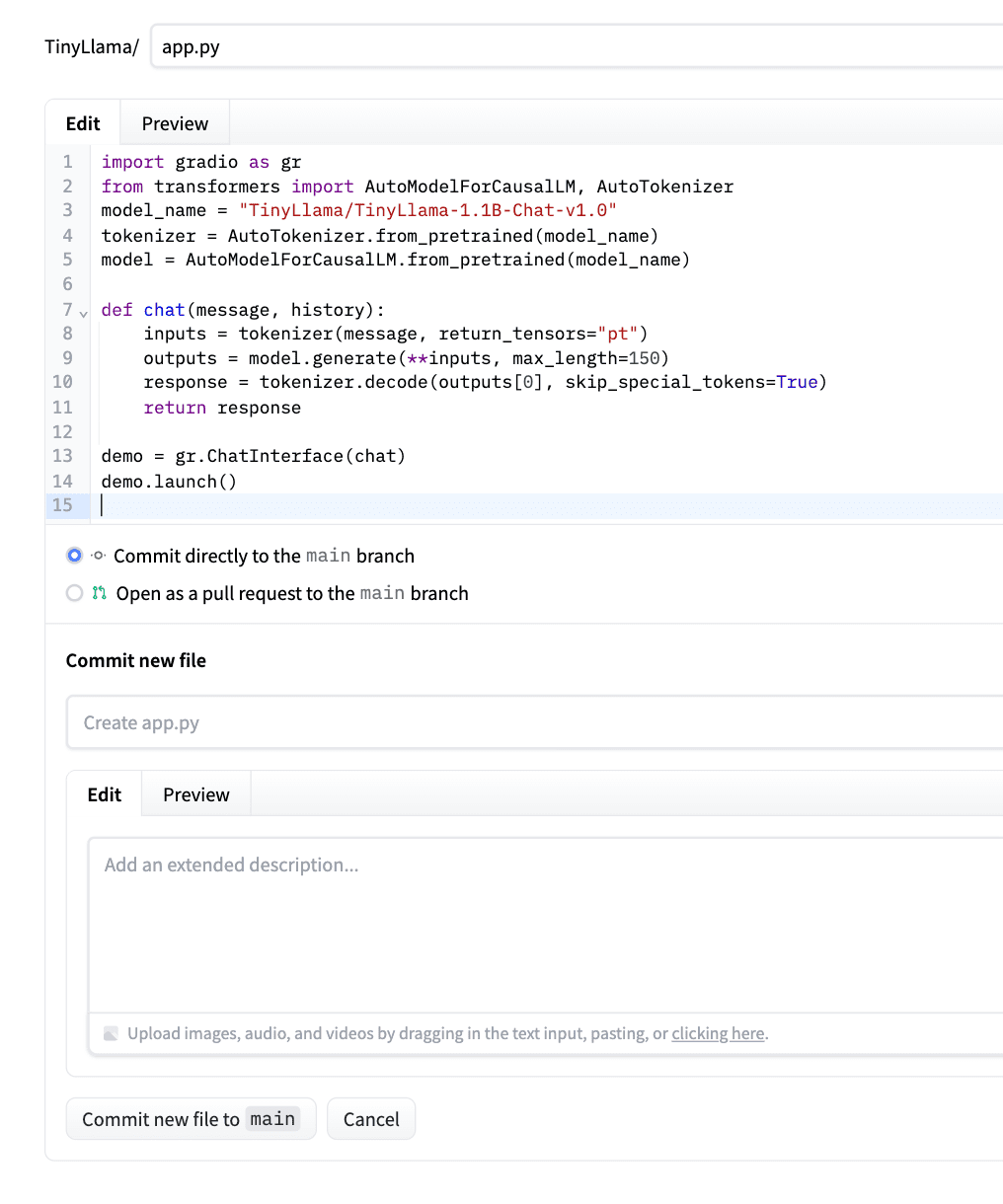
Hugging Face는 자동으로 이를 감지하고, 종속성을 설치하고, 앱을 배포합니다.

그 시간 동안 requirements.txt 파일을 열지 않으면 이와 같은 오류가 발생합니다.

// 3단계: 요구 사항.txt 만들기
화면 오른쪽 상단에 있는 “파일”을 클릭하세요.

여기에서 아래 스크린샷처럼 “새 파일 만들기”를 클릭하세요.

다음 스크린샷에 표시된 대로 파일 이름을 “requirements.txt”로 지정하고 Python 라이브러리 3개를 추가합니다(transformers, torch, gradio).
트랜스포머 여기서는 모델을 로드하고 토큰화를 처리합니다. 토치 신경망 엔진을 제공하므로 모델을 실행합니다. Gradio는 사용자가 모델과 채팅할 수 있도록 간단한 웹 인터페이스를 만듭니다.

// 4단계: 배포된 모델 실행 및 테스트
녹색 표시등 “실행 중”이 표시되면 완료되었음을 의미합니다.

이제 테스트해 보겠습니다.
먼저 여기에서 앱을 클릭하여 테스트할 수 있습니다.

이를 사용하여 이상값을 감지하는 Python 스크립트를 작성해 보겠습니다. 쉼표로 구분된 값 (CSV) 파일은 z-점수를 사용하고 사분위간 범위 (IQR).
테스트 결과는 다음과 같습니다.
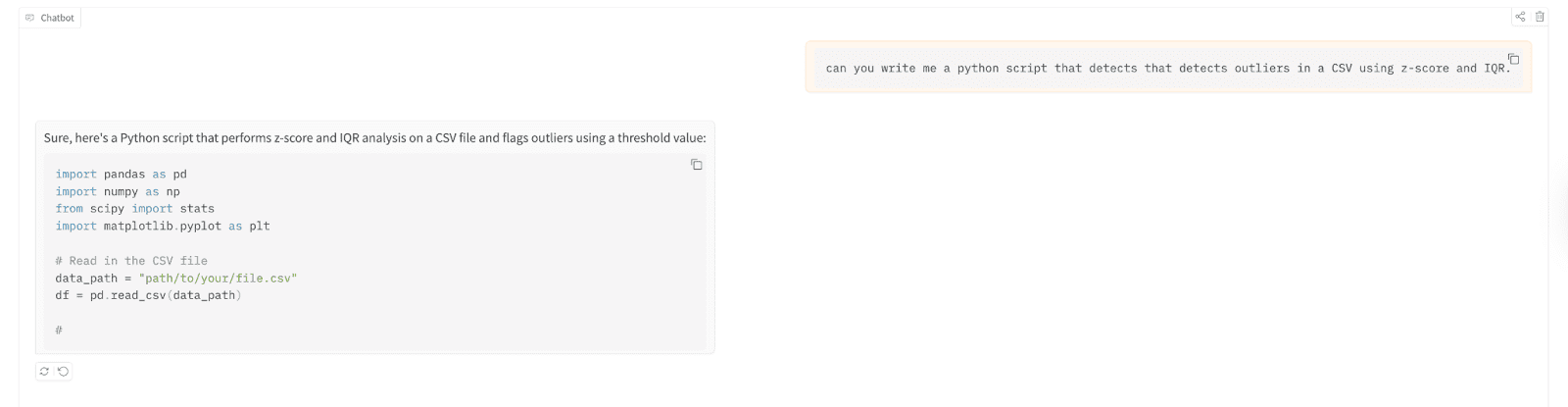
// 방금 구축한 배포 이해
그 결과 이제 10억 개 이상의 매개변수 언어 모델을 가동할 수 있으며 터미널을 건드릴 필요도 없고, 서버를 설정할 필요도 없고, 1달러도 지출할 필요가 없습니다. Hugging Face는 호스팅, 컴퓨팅, 확장(어느 정도)을 관리합니다. 더 많은 트래픽을 위해 유료 계층을 사용할 수 있습니다. 그러나 실험 목적으로는 이것이 이상적입니다.
가장 좋은 학습 방법은? 먼저 배포하고 나중에 최적화하세요.
# 다음 단계: 모델 개선 및 확장
이제 작동하는 챗봇이 생겼습니다. 하지만 TinyLlama는 시작에 불과합니다. 더 나은 대응이 필요한 경우 동일한 프로세스를 사용하여 Phi-2 또는 Mistral 7B로 업그레이드해 보세요. 모델명만 바꾸시면 됩니다 app.py 컴퓨팅 성능을 조금 더 추가하세요.
더 빠른 응답을 위해서는 양자화를 살펴보세요. 또한 모델을 데이터베이스에 연결하거나, 대화에 메모리를 추가하거나, 자신의 데이터에 맞게 미세 조정할 수도 있으므로 상상력이 제한됩니다.
네이트 로시디 데이터 과학자이자 제품 전략 분야의 전문가입니다. 그는 또한 분석을 가르치는 부교수이기도 하며 데이터 과학자가 상위 기업의 실제 인터뷰 질문을 사용하여 인터뷰를 준비하는 데 도움이 되는 플랫폼인 StrataScratch의 창립자이기도 합니다. Nate는 취업 시장의 최신 동향에 대해 글을 쓰고, 인터뷰 조언을 제공하고, 데이터 과학 프로젝트를 공유하고, SQL의 모든 것을 다룹니다.












Post Comment