Xgboost 회귀 분석 알고리즘으로 AD보기 가능성을 예측합니다

데이터에서 통찰력을 추출하고 의사 결정 프로세스에서이를 활용하는 것도 점점 더 널리 퍼지고 있습니다. 오늘날이 접근법은 디지털 광고를 포함한 다양한 도메인에서 영향력있는 작업을 가능하게합니다. 디지털 광고의 세계에서 광고에 노출 된 사용자와 광고를 표시하는 플랫폼 간의 상호 작용은 매우 중요합니다.
광고주와 게시자 간의 일치는 수요 측면 플랫폼 (DSP) 및 SSP (Supply-Side Platforms)에서 밀리 초 이내에 수행 된 경매에 의해 촉진됩니다. 정확한 매칭은 사용자 만족도와 수익 관리 모두에 필수적입니다. 이와 관련하여 가장 중요한 KPI 중 하나는 광고보기 가능성.
올바른 청중에게 올바른 광고를 제공하는 것은 광고 예산 효율성을 극대화하고 사용자 만족도를 향상시키는 데 중요한 역할을합니다. 이 기사에서는 광고보기 성 속도를 예측하기위한 기계 학습 모델을 개발할 것입니다. 이 작업에 매우 효과적인 XGBoost regressor 알고리즘을 사용하겠습니다.
모델링 프로세스
1. 라이브러리 가져 오기
첫 번째 단계는 프로젝트에서 사용할 파이썬 라이브러리를 가져 오는 것입니다. 누락 된 라이브러리가 발생하면 라이브러리를 사용하여 설치해야합니다. pip install 명령.
2. 데이터 준비
다음으로 모델에서 사용할 데이터 세트를 가져옵니다.

데이터를 가져 오면 몇 가지 전처리 단계가 필요합니다. 예를 들어, creative_adsize AD 크기를 나타내는 변수는 초기에 범주 형 변수입니다 (예 : “640×480”). 그러나 AD 크기는 대상 변수에 크게 영향을 미치기 때문에이 기능이 광고 차원에 대한 모델의 이해를 향상시키기 위해이 기능을 숫자 형식으로 변환합니다.
또한 변수 값 내에서 특이 치를 식별하고 제거하고 변수의 특성에 따라 평균을 전가하거나 다른 적절한 방법을 적용하여 누락 데이터를 처리합니다.

우리는 또한 파생됩니다 month 그리고 day 계절적 효과와 달의 시작 또는 끝과 같은 요인이므로 날짜 기능의 변수는 AD 시청률에 영향을 줄 수 있습니다.
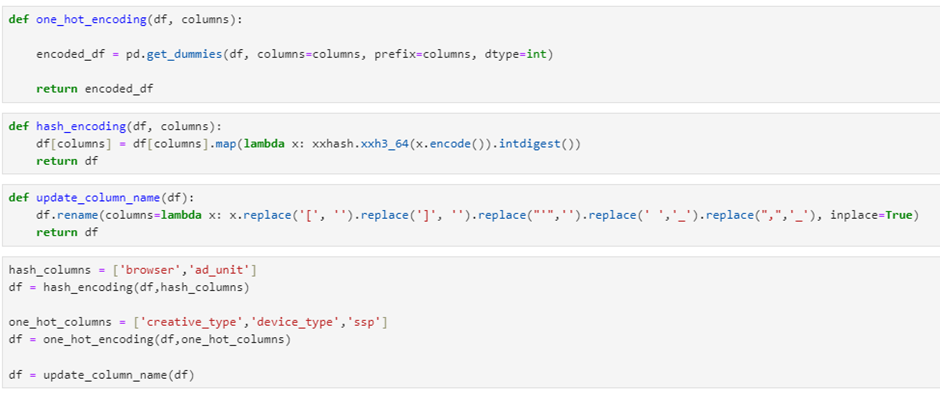
모델에 범주 형 변수를 포함시키기 위해 인코딩을 수행합니다.
- 한 가지 인코딩. 제한된 수의 범주가있는 변수에 적용됩니다.
creative_typeSSP 및device_type. - 해시 인코딩. 브라우저 및와 같이 더 많은 수의 범주가있는 변수에 사용됩니다.
ad_unit.
모델의 최종 기능 세트에는 다음이 포함됩니다.
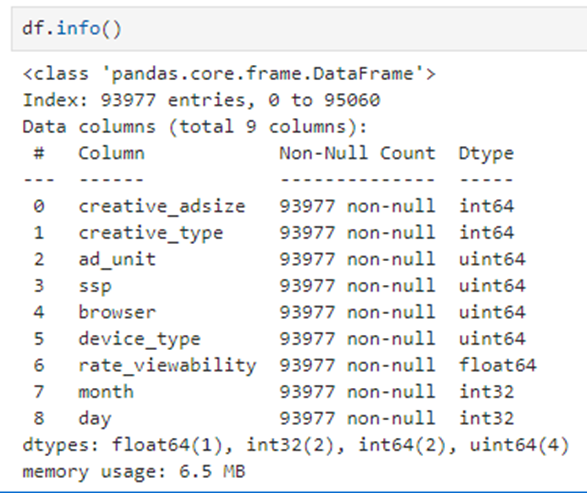
열의 설명은 다음과 같습니다.
| 변수 | 설명 |
|---|---|
|
creative_adsize |
광고의 크기. |
|
Creative_type |
예를 들어 이미지 또는 비디오와 같은 광고 유형. |
|
ad_unit |
웹 사이트에 광고의 배치 ID. |
|
SSP |
공급 측면 플랫폼. |
|
브라우저 |
사용자의 웹 사이트 브라우저. |
|
device_type |
사용자의 장치 유형 (예 : 전화, 개인용 컴퓨터, 태블릿). |
|
rate_viewability |
이 모델의 대상 변수는 광고의 시청률을 보여줍니다. |
|
월 |
사용자 방문 월. |
|
낮 |
사용자 방문 당일. |
3. 모델 훈련
인코딩 및 기능 엔지니어링 프로세스를 완료 한 후 데이터를 교육 및 테스트 세트로 나눕니다. 또한 XGBoost 알고리즘에는 모델의 일반화 능력을 향상시키기 위해 설계된 수많은 매개 변수가 포함되어 있습니다.
특정 데이터 세트 및 작업에 가장 적합한 매개 변수 값을 결정하려면 그리드 검색, 임의 검색 또는 베이지안 최적화와 같은 하이퍼 파라미터 최적화 방법을 사용할 수 있습니다. 이 방법은 다양한 매개 변수 조합을 체계적으로 탐색하여 모델 성능의 균형을 맞추고 과결을 방지하는 최적의 설정을 찾는 데 도움이됩니다.

4. 모델 성능 평가
모델의 성능을 평가하기 위해 우리는 같은 메트릭을 사용합니다 평균 제곱 오류 (MSE) 그리고 R².
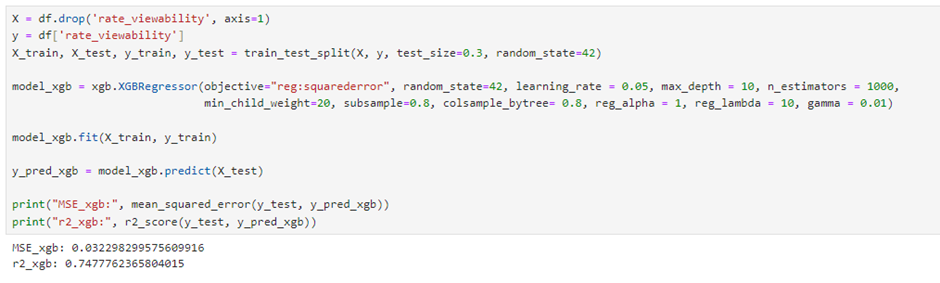
R² 및 평균 제곱 오차 점수를 평가할 때 R² 값이 높고 평균 제곱 오차가 낮을 것으로 예상됩니다. 그러나 모델이 과적으로 적합 할 수 있으므로 지나치게 높은 R² 값이 항상 좋은 결과는 아닙니다. 이 측면도 고려해야하며,이 텍스트에서 과적으로 과적하고 부적합한 위험을 평가하는 방법에 대해 논의 할 것입니다.
0.74의 r² 값은 현재 우리 모델에 충분 해 보입니다. 우리의 MSE 값도 0.03이며 나쁘지 않습니다. 결과를 개선하기 위해 더 나은 성능을 위해 데이터 세트 크기를 늘리거나 새로운 기능을 추가하거나 미세 조정 모델 매개 변수를 추가 할 수 있습니다.
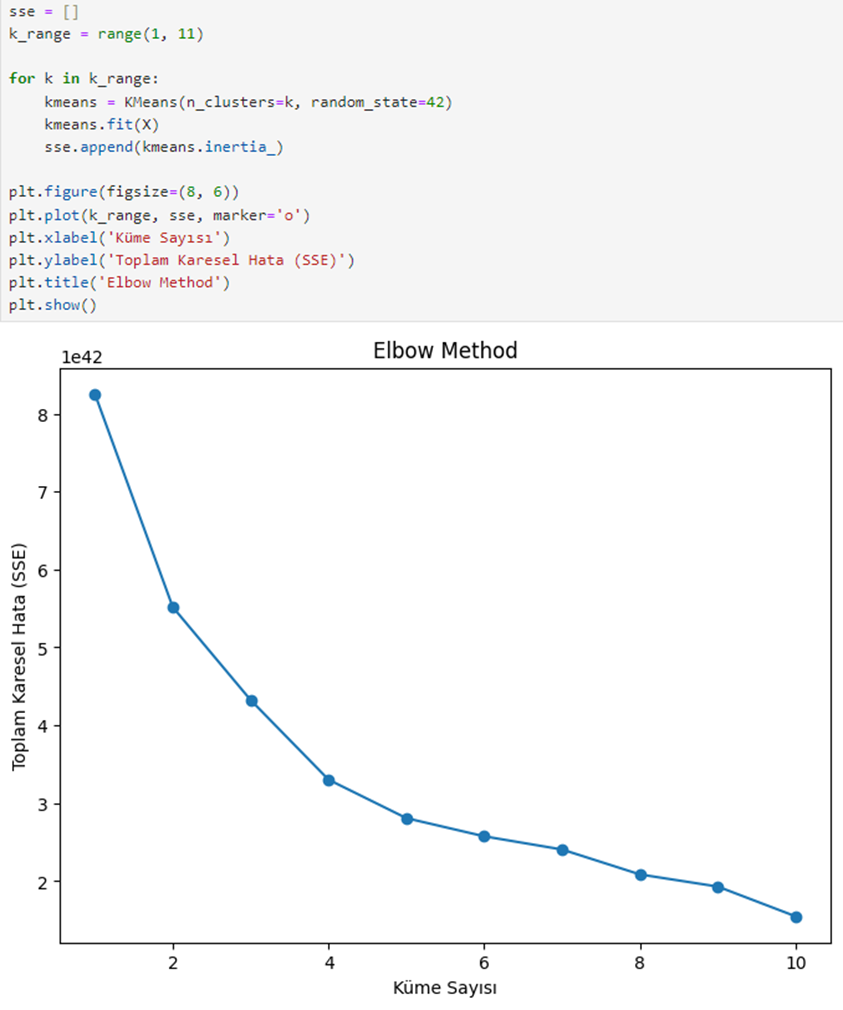
모델이 다른 샘플에서 일관되게 수행되도록하기 위해 K- 폴드 크로스 검증. 우리는 그것을 사용하여 k의 최적 값을 결정합니다 팔꿈치 방법k를 4로 설정합니다.
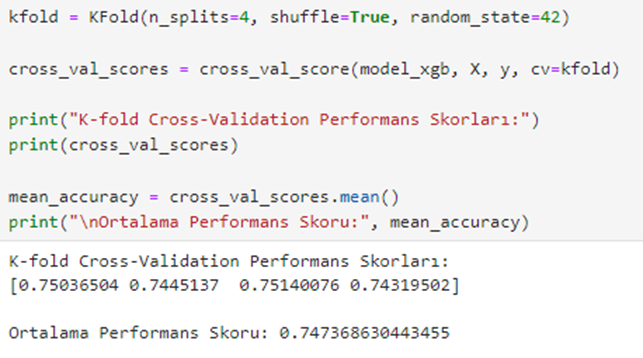
4 배 모두에 대해 R² 점수의 균형 잡힌 분포를 관찰합니다. 그것들은 0.75, 0.74, 0.75 및 0.74입니다.
k-cross 검증을 사용한 테스트 결과가 불균형 된 경우 모델의 R² 값과 크게 다른 값을 가진 클러스터를 별도로 검사해야했을 것입니다.
5. 기능 중요성 분석
어떤 변수가 모델에 가장 중요한 영향을 미치는지 이해하기 위해 순열 중요성 방법. 이 분석은 독립 변수가 종속 변수에 어떤 영향을 미치는지 시각화하는 데 도움이됩니다.
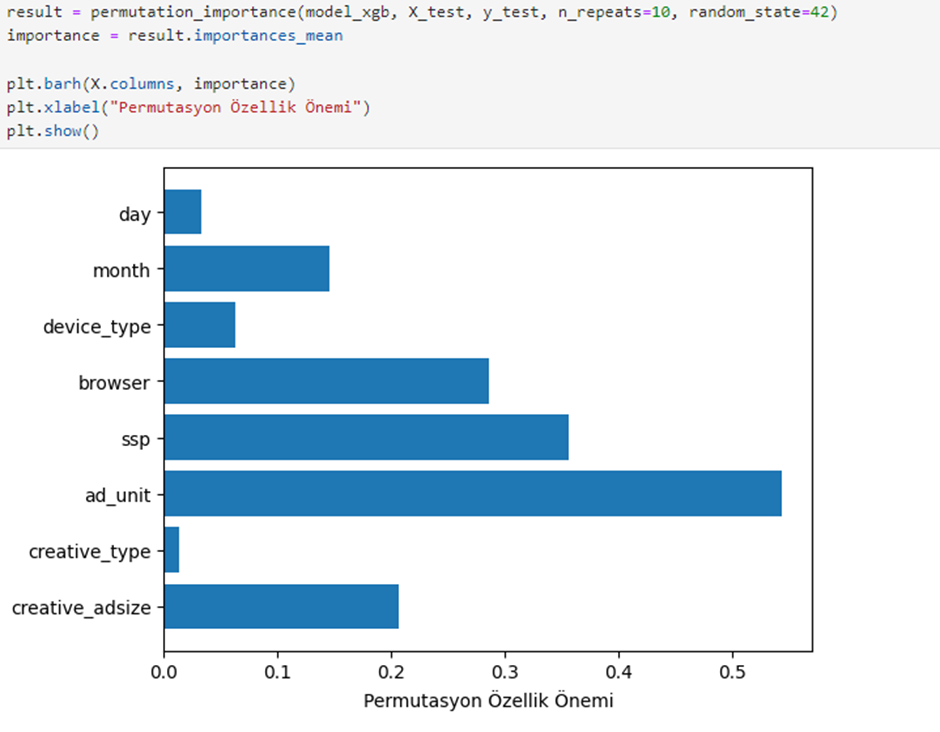
순열 중요도 메소드를 사용하여 가장 영향력있는 기능은 ad_unit,,, SSP,,, browser,,, creative_adsize.
한편, 영향력이 가장 적은 기능에는 다음이 포함됩니다 month,,, device_type,,, day그리고 creative_type.
모델 성능에 더 큰 영향을 미치는 기능을 분석하려면 순열 방법 이외의 방법이 있습니다. 증가, 체중 및 쉐이프는 그 중 일부입니다. 자세한 분석이 필요한 경우 쉐이프 값을 사용할 수 있습니다.
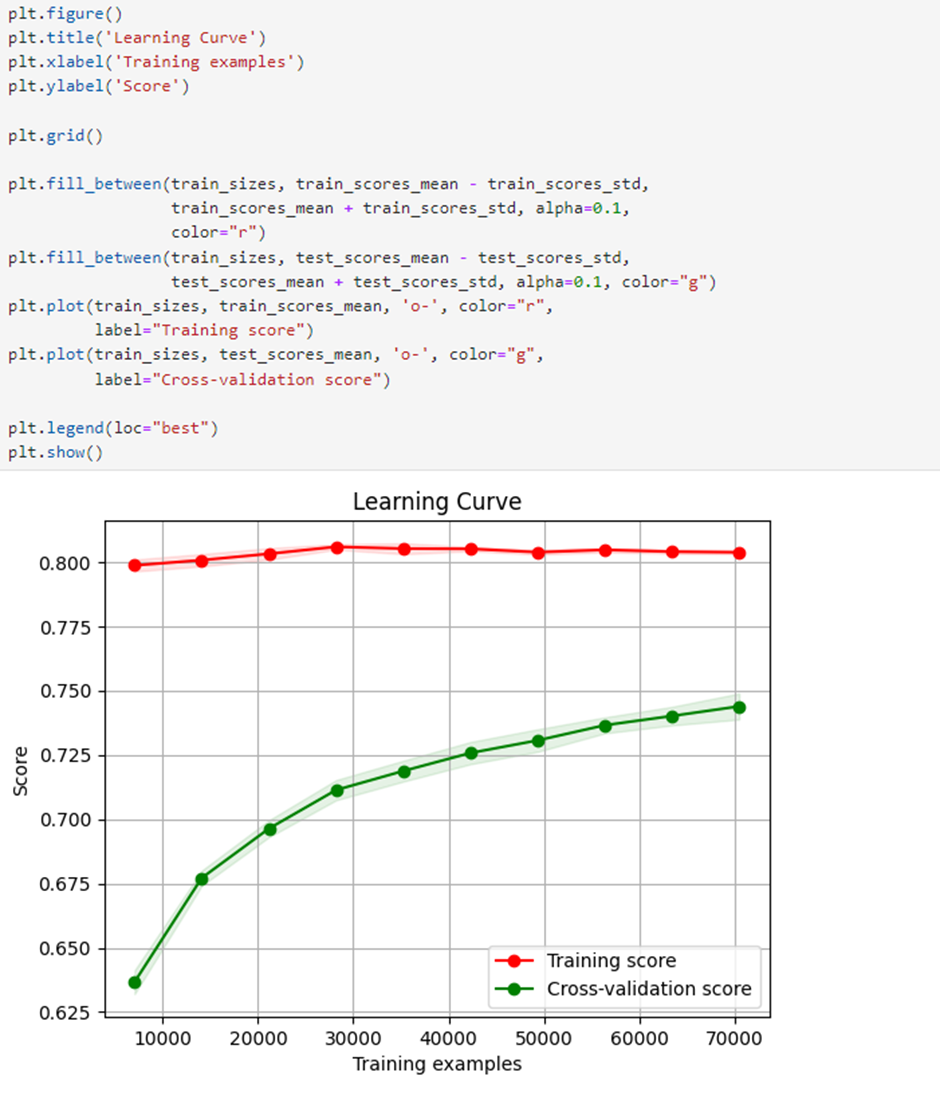
6. 과적 및 부적합 점검
모델이 과적으로 부적절하거나 부적합한 지 확인하려면 사용합니다. 학습 곡선 분석. 시각화는 과적으로 적합하거나 부적합의 징후가 표시되지 않습니다. 또한 데이터 크기가 증가함에 따라 테스트 모델 성능이 향상됩니다.
처음에는 과적이지만 데이터의 양이 증가함에 따라 과적으로 적합성이 감소하고 모델이 더 잘 일반화된다는 것을 알 수 있습니다.
결론
이 기사에서는 XGBOOST Regressor 알고리즘을 사용하여 AD보기 가능성 속도를 예측하는 모델을 개발했습니다. 우리는이 연구가 당신에게도 도움이되기를 바랍니다. 당신의 생각과 질문을 자유롭게 공유하십시오!













Post Comment