과학자들은 AI를 가르쳐서 더 똑똑하고 선명한 재료 그래프를 구축했습니다.

저자 :
(1) Yanpeng YE, 뉴 사우스 웨일즈 대학교, 켄싱턴, NSW, Greendynamics Pty. Ltd, Kensington, NSW, Australia 및이 저자들은이 작품에 똑같이 기여했습니다.
(2) Jie Ren, Greendynamics Pty. Ltd, 호주 NSW, Kensington, 중국 홍콩 홍콩 시립 대학교 재료 과학 및 공학과,이 저자들은이 작품에 똑같이 기여했습니다.
(3) Shaozhou Wang, Greendynamics Pty. Ltd, Kensington, NSW, Australia[email protected]);
(4) Yuwei Wan, Greendynamics Pty. Ltd, 켄싱턴, NSW, 호주 및 중국 홍콩 시티 대학교 언어 및 번역부;
(5) Imran Razzak, 뉴 사우스 웨일즈 대학교 컴퓨터 과학 및 공학부, 호주 NSW 켄싱턴;
(6) Tong Xie, Greendynamics Pty. Ltd, 켄싱턴, NSW, 호주 및 뉴 사우스 웨일즈 대학교, 뉴 사우스 웨일즈 대학교 (New South Wales University)[email protected]);
(7) Wenjie Zhang, 뉴 사우스 웨일즈 대학교 (New South Wales University of Computer Science and Engineering)[email protected]).
편집자 주 :이 기사는 광범위한 연구의 일부입니다. 당신은 9의 8 부를 읽고 있습니다. 아래의 나머지를 읽으십시오.
링크 표
논의
이 연구에서 우리는 미세 조정 된 LLM에 의해 기능적 재료 kg를 구성하고 모든 정보의 추적 성을 보장합니다. 이 과정에서 우리는 두 가지 주요 과제와 해당 솔루션을 제안했습니다. 1) 미세 조정 LLM은 교육 세트 볼륨의 요구 사항을 줄이지 만 교육 세트의 각 데이터에 대해 더 높은 품질이 필요합니다. 교육 데이터 세트의 품질이 제한되면 NER 및 RE의 성능은 좋지 않습니다. 추론 결과에서 자동으로 교육 세트 데이터를 재귀 적으로 생성하는 것은 좋은 솔루션입니다. 간단한 수동 점검 후 각 추론의 높은 리콜 및 정밀 데이터를 훈련 세트에 넣을 수 있습니다. 2) 미세 조정 된 LLM은 NER 및 RE 작업에서 잘 수행하지만 ER 작업의 경우 동일하게 표시 할 수 없습니다. 그러나 ER은 그래프 구성에서도 중요합니다. 이 문제를 해결하기 위해 ChemDataExtractor, MAT2VEC, Word Embedding Clustering을 포함한 몇 가지 ER 방법 및 기술을 적용하고 에너지 재료에 대한 전문가 사전 저장 정보를 구성합니다. 이러한 방법과 기술은 높은 성능 작업을 달성 할 수있을뿐만 아니라 일부 잘못된 엔티티와 관계를 제거 할 수 있습니다.
우리의 방법과 FMKG의 신뢰성을 더 잘 보여주기 위해, 우리는이를 기존 구조 정보 추출 방법 및 재료 kg과 비교합니다. 우리는 John Dagdelen et al.[21] 텍스트에서 구조화 된 정보를 추출합니다. 차이점은 ER 방법을 적용하여 엔티티와 관계를 수정하고 그래프 구성 전에 ER 작업을 완료한다는 것입니다. 우리는 Nerre의 평가 데이터 세트에서 파이프 라인을 평가했습니다. 교차 데이터 세트 평가는 다른 레이블 (예 : “캐소드”)에서 엔티티의 여러 타당한 주석의 유연성을 허용합니다.



Nerre는 “Application”라벨에 배치되지만 전문가는 “캐소드”와 “애노드”가 응용 프로그램 인 “배터리”의 구성 요소이기 때문에 “디스크립터”에 배치하는 경향이 있으며, 결과를 표 5에 제시했습니다. 결과로부터 결과에서 결과를 Nerre 작업에 비해 레이블 전체에서 리콜을 약간 낮게 보이지만, 우리의 방법은 Precrision에서 경쟁력을 유지한다는 것이 분명합니다. KG 구성의 주요 목표는 데이터의 정확성을 보장하는 것이라고 생각하기 때문입니다. 따라서, ER 과정에서, 우리의 전략은 더 높은 정밀도와 대가로 리콜의 일부를 희생하는 경향이 있습니다. 그러나 리콜과 정밀도를 모두 고려할 때, 우리의 방법은 Nerre와 비교하여 “약어”, “응용 프로그램”, “구조/단계”및 “설명 자”라벨에서 F1에서 더 높아지고, “약어”의 개선은 Nerre의 정밀도로 인해 특히 중요합니다. 이것은 우리의 ER 파이프 라인의 이점을 강조하고 FMKG의 신뢰성을 간접적으로 증명합니다.


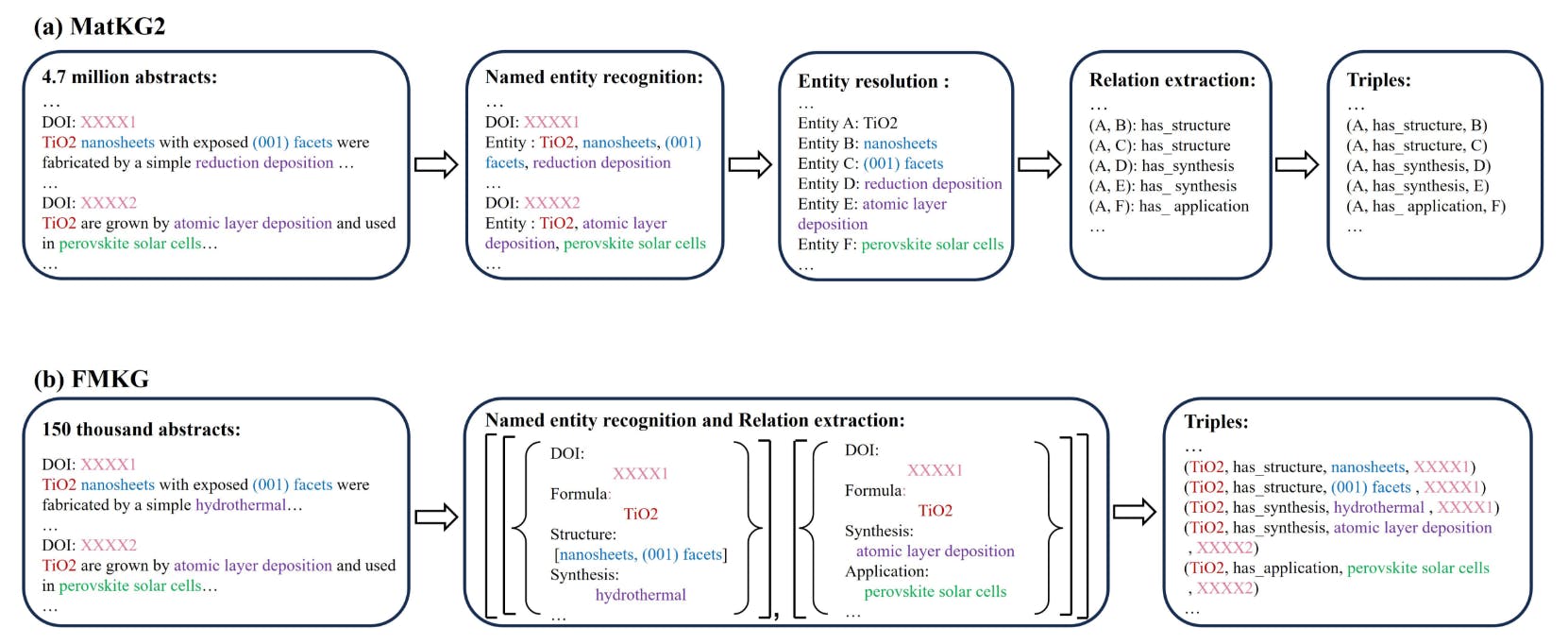
일반적인 자료에 전념하는 지식 그래프는 드 rare니다. 우리의 토론에서, 우리는 MATKG2와 비교합니다[15]그림 5에 묘사 된 바와 같이 MATKG2와 FMKG 간의 건축 방법론의 차이를 보여줍니다. MATKG2의 구성은 다중 단계 NER 및 RE 파이프 라인에 포함되며, 이는 관계의 근원을 포착 할 수 없습니다. 우리의 방법에서, 우리는 단일 LLM을 사용하는 엔터티 인식 및 관계 추출에 대해 조사 된 엔드 투 엔드 방법을 사용합니다. 각 트리플의 공급원을 KG로 유지할 수있을뿐만 아니라 KG의 사실 기반을 향상시킬 수있을뿐만 아니라 RE 작업에서도 더 나은 성능을 발휘할 수 있습니다.
KG는 항상 재료 과학과 같은 최첨단 분야에서 항상 역동적입니다. LLM은 교육 과정에서 많은 양의 지식을 내면화하므로 새로운 노드와 관계가 나타나는 경우에도 우수한 추론을 수행하여 KG를 쉽게 업데이트 할 수 있습니다. 게다가, 우리의 작업은 다른 재료 연구자들이 우리의 결과를 훈련 데이터 세트로 사용하여 FMKG를 계속 구축 할 수있는 출발점, 사전, ChemDataExtractor 및 MAT2VEC를 사용하여 ER 작업을 달성 할 수있는 출발점입니다. 우리의 방법은 전체 용지로 확장하고보다 기능적인 재료 정보를 추출하여 더 크고 포괄적 인 기능 지식 그래프를 구성 할 수 있습니다. 게다가, 우리의 파이프 라인은 다른 특수 영역에서도 도메인-특이 적 KG를 구성하기 위해 사용될 수 있습니다.










: 소형, 예산, 액세서리")



Post Comment