대형 언어 모델은 게임 상태 시뮬레이션의 미래입니까?

::: 정보
저자 :
(1) 애리조나 대학교 Ruoyao Wang ([email protected]);
(2) 뉴욕 대학교 그레이엄 토드 ([email protected]);
(3) Ziang Xiao, Johns Hopkins University ([email protected]);
(4) Xingdi Yuan, Microsoft Research Montréal ([email protected]);
(5) Marc-Aalexandre 측, Microsoft Research Montreal ([email protected]);
(6) Peter Clark, Alen Institute for AI ([email protected]);
(7) Peter Jansen, Arizona University 및 Alen Institute for AI ([email protected]).
:::
링크 표
초록 및 1. 소개 및 관련 작업
-
방법론
2.1 LLM-SIM 작업
2.2 데이터
2.3 평가
-
실험
-
결과
-
결론
-
제한 및 윤리적 관심사, 인정 및 참고 문헌
A. 모델 세부 사항
B. 게임 전환 예
C. 게임 규칙 생성
D. 프롬프트
E. GPT-3.5 결과
F. 히스토그램
추상적인
가상 환경은 복잡한 계획 및 의사 결정 작업의 발전을 벤치마킹하는 데 중요한 역할을하지만 손으로 구축하는 데 비싸고 복잡합니다. 현재 언어 모델 자체가 세계 시뮬레이터 역할을하여 행동이 다른 세계 상태를 변화시키는 방법을 올바르게 예측하여 광범위한 수동 코딩의 필요성을 우회 할 수 있습니까? 우리의 목표는 텍스트 기반 시뮬레이터의 맥락 에서이 질문에 답하는 것입니다. 우리의 접근 방식은 Bytesized32-State-Prediction이라는 새로운 벤치 마크를 구축하고 사용하는 것입니다. 우리는 이것을 사용하여 처음으로 LLM이 텍스트 기반 세계 시뮬레이터 역할을 할 수있는 방법을 처음으로 직접 정량화합니다. 우리는이 데이터 세트에서 GPT-4를 테스트하고 인상적인 성능에도 불구하고 여전히 더 이상의 혁신이없는 신뢰할 수없는 세계 시뮬레이터라는 것을 알게됩니다. 따라서이 작업은 현재 LLM의 기능과 약점에 대한 새로운 통찰력과 새로운 모델이 나타날 때 미래의 진행 상황을 추적하는 새로운 벤치 마크에 기여합니다.
1 소개 및 관련 작업
세상을 시뮬레이션하는 것은 그것을 공부하고 이해하는 데 중요합니다. 그러나 대부분의 경우, 이용 가능한 시뮬레이션의 폭과 깊이는 구현에 몇 주 또는 몇 달에 걸쳐 인간 전문가 팀의 광범위한 작업이 필요하다는 사실에 의해 제한됩니다. LLMS (Large Language Models)의 최근 발전은 사전 훈련 데이터 세트에 포함 된 막대한 양의 지식을 활용하여 대체 접근 방식을 지적했습니다. 그러나 그들은 시뮬레이터로 직접 사용할 준비가 되었습니까?
\ 우리는이 질문을 자연스럽게 자연스럽게 표현하고 자연 언어로 환경과 역학을 자연스럽게 표현하고 의사 결정 과정의 발전의 일부로 오랫동안 사용되어 왔습니다 (Comté et al., 2018; Fan et al., 2020; Urbanek et al., 2019; Shridhar et al., 2020; Hausknecht et al., 2022; 정보 추출 (Ammanabrolu and Hausknecht, 2020; Adhikari et al., 2020) 및 인공 추론 (Wang et al., 2022).
\
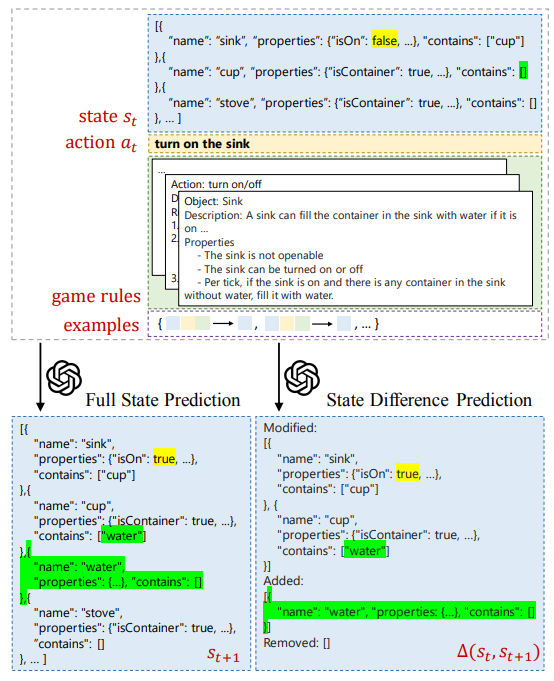
\ 광범위하게 말하면, 세계 모델링 및 시뮬레이션의 맥락에서 LLM을 활용하는 두 가지 방법이 있습니다. 첫 번째는입니다 신경 상징적: 많은 노력은 언어 모델을 사용하여 공식적인 계획 또는 추론을 허용하는 상징적 표현으로 코드를 생성합니다 (Liu et al., 2023; Nottingham et al., 2023; Wong et al., 2023; Tang et al., 2024). 계획을 통한 추론 (RAP) (Hao et al., 2023)은 그러한 접근법 중 하나입니다. LLM 프라이어를 사용하여 세계 모델을 구성한 다음 전용 계획 알고리즘을 사용하여 에이전트 정책을 결정합니다 (LLM 자체가 플래너로 직접 행동하기 위해 계속 노력하고 있습니다 (Valmeekam et al., 2023)). 마찬가지로, Bytesized32 (Wang et al., 2023)는 대규모 Python 프로그램의 형태로 과학적 추론 개념의 시뮬레이션을 인스턴스화하는 작업을 수행합니다. 이러한 노력은 두 번째 노력과 대조적이며 비교적 덜 연구 된 접근 방식 직접 시뮬레이션. 예를 들어, AI-Dungeon은 언어 모델의 생성 된 출력을 통해 순전히 게임 세계를 나타냅니다 (Walton, 2020). 이 작업에서 우리는 가상 환경을 직접 시뮬레이션하기위한 LLM의 능력에 대한 첫 번째 정량적 분석을 제공합니다. 우리는 사용합니다 구조적 표현 JSON 스키마에서 스캐 폴드로서 시뮬레이션 정확도를 향상시키고 다양한 조건에서 LLM의 능력을 직접 조사 할 수 있습니다.
\ GPT-4 (Achiam et al., 2023)의 체계적인 분석에서, 우리는 LLM이 상담원 행동과 직접 관련이없는 상태 전환과 산술, 상식 또는 과학적 추론이 필요한 전환을 포착하지 못한다는 것을 발견했다. 다양한 조건에 걸쳐 세계 국가의 사소한 변화가 발생하는 전환의 경우 모델 정확도가 59.9%를 초과하지 않습니다. 이러한 결과는 다운 스트림 작업에 유망하고 유용하지만 LLM은 아직 추가 혁신없이 신뢰할 수있는 세계 시뮬레이터 역할을 할 준비가되지 않았 음을 시사합니다.[1]
\
::: 정보이 논문은입니다 Arxiv에서 사용할 수 있습니다 CC에 따라 4.0 라이센스.
:::
[1] 코드 및 데이터는 com/cognitiveailab/gpt-simulator에서 제공됩니다.













Post Comment