Oracle 23 AI의 JSON 관계형 이원성 잠금 해제

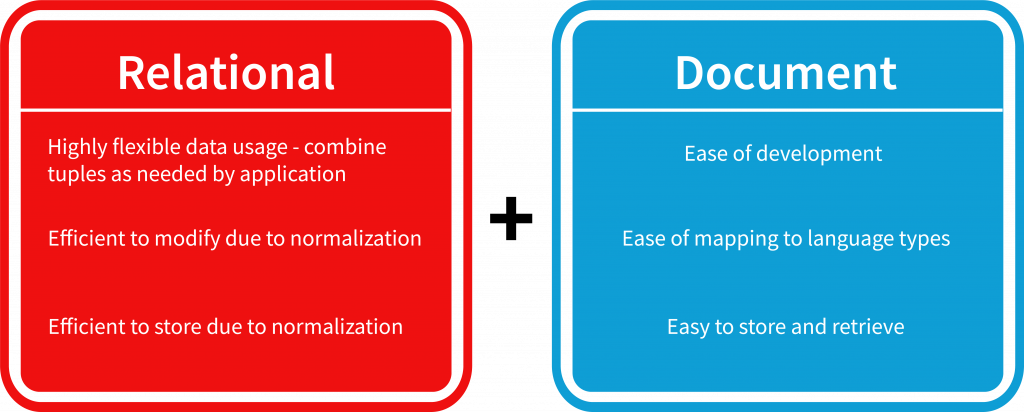
오라클 23AI ‘s JSON 관계형 이원성 JSON과 관계형 데이터 간의 격차를 해소하여 두 형식의 데이터를 완벽하게 쿼리하고 업데이트 할 수 있습니다. 이 기능을 통해 개발자는 하이브리드 데이터 모델을 효율적으로 관리하고 애플리케이션 워크 플로우를 단순화하며 데이터 변환 오버 헤드를 줄일 수 있습니다.
또한 JSON과 관계형 형식의 데이터를 원활하게 쿼리하고 업데이트 할 수 있도록하여 최신 응용 프로그램에 대한 데이터 처리를 단순화 할 수 있습니다.
예제에 대한 테이블 설정
JSON 관계형 이중성을 탐색하려면 두 가지 관계형 테이블을 만들고 채 웁니다. departments 그리고 employees. 이것들은 JSON 조회의 기초가 될 것입니다.
--- DROP existing TABLES (IF ANY)
DROP TABLE IF EXISTS employees purge;
DROP TABLE IF exists departments purge;
--- CREATE departments TABLE
CREATE TABLE departments
(
dept_id NUMBER(2) PRIMARY KEY,
dept_name VARCHAR2(50),
location VARCHAR2(50)
);
--- CREATE employees TABLE
CREATE TABLE employees
(
emp_id NUMBER(4) PRIMARY KEY,
emp_name VARCHAR2(50),
ROLE VARCHAR2(50),
salary NUMBER(10,2),
dept_id NUMBER(2) REFERENCES departments(dept_id)
);
--- INSERT sample data
INSERT INTO departments VALUES
(
1,
'Engineering',
'San Francisco'
);
INSERT INTO departments VALUES
(
2,
'Marketing',
'New York'
);
INSERT INTO departments VALUES
(
3,
'HR',
'Chicago'
);
INSERT INTO employees VALUES
(
1001,
'Alice',
'Engineer',
95000,
1
);
INSERT INTO employees VALUES
(
1002,
'Bob',
'Manager',
120000,
1
);
INSERT INTO employees VALUES
(
2001,
'Carol',
'Marketer',
70000,
2
);
INSERT INTO employees VALUES
(
3001,
'Eve',
'HR Specialist',
80000,
3
);
COMMIT;JSON과 관련된 이중성보기 생성
JSON 관계형 이중성보기는 관계형 및 JSON 데이터를 통합 JSON 기반 인터페이스로 결합합니다. 보기를 만들어 봅시다 department_details 이로 인해 부서 정보와 직원을 JSON 문서로 통합합니다.
SQL 구문
CREATE
OR
replace json relational duality VIEW department_details AS
SELECT json { '_id': d.dept_id,
'departmentName': d.dept_name,
'location': d.location,
'employees': [
SELECT json { 'employeeId': e.emp_id,
'employeeName': e.emp_name,
'role': e.ROLE,
'salary': e.salary }
FROM employees e WITH
INSERT
UPDATE
DELETE
WHERE e.dept_id = d.dept_id ] }문서 구조를 정의하고 데이터 소스를 지정하여 JSON 관련 이중성보기를 만듭니다. 다음 예에서는 뷰를 만듭니다 department_details SQL 또는 JSON 사용.
이 견해에는 각 부서의 직원 배열을 포함한 부서 정보가 나와 있습니다. 각 테이블에 대해, 우리는 기본 테이블에서 수행 할 수있는 가능한 작업을 정의합니다. 이 예에서는 다음을 허용 할 수 있습니다 INSERT,,, UPDATE그리고 DELETE 두 테이블에 대한 작업.
JSON 데이터 쿼리
SQL> desc department_details
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
DATA
SQL> SELECT JSON_SERIALIZE(d.data PRETTY) FROM department_details d;
샘플 출력 :
{
"_id": 1,
"departmentName": "Engineering",
"location": "San Francisco",
"employees": [
{
"employeeId": 1001,
"employeeName": "Alice",
"role": "Engineer",
"salary": 95000
},
{
"employeeId": 1002,
"employeeName": "Bob",
"role": "Manager",
"salary": 120000
}
]
}
JSON보기로 데이터 업데이트
JSON 관계형 이중성을 사용하면 JSON 구조를 사용하여 데이터를 직접 업데이트 할 수 있습니다.
UPDATE department_details d
SET d.data = json { '_id': 1,
'departmentName': 'Engineering & Development',
'location': 'San Francisco',
'employees': [ { 'employeeId': 1001,
'employeeName': 'Alice',
'role': 'Senior Engineer',
'salary': 105000 } ] }
WHERE d.data."_id" = 1;이 업데이트는 JSON 추상화를 유지하면서보기 뒤에있는 관계형 테이블을 수정합니다.
우리는 또한 테이블을 사용하여 업데이트 할 수 있습니다 JSON_TRANSFORM그래서 우리는 테이블을 JSON 테이블 인 것처럼 취급하고 있습니다.
update departments_dv d
set d.data = json_transform(d.data, set '$.location' = 'CHICAGO2')
where d.data."_id" = 30;
select * from dept where deptno = 30;
DEPTNO DNAME LOC
---------- -------------- -------------
30 SALES CHICAGO2새 레코드 추가
단일 JSON 문서를 사용하여 새 부서와 직원을 삽입 할 수 있습니다.
INSERT INTO department_details d
(
data
)
VALUES
(
json { '_id': 4,
'departmentName': 'IT Support',
'location': 'Austin',
'employees': [ { 'employeeId': 4001,
'employeeName': 'Dave',
'role': 'Technician',
'salary': 65000 } ] }
);새로운 부서와 직원은 JSON과 관계형 테이블 모두에 나타납니다.
데이터 삭제
부서를 삭제하면 관련 직원도 제거됩니다.
DELETE FROM department_details d WHERE d.data."_id" = 3;
1 row deleted.
SQL>_etag로 낙관적 잠금
각 JSON 문서에는 a가 포함됩니다 _etag 안전한 동시 업데이트 보장 낙관적 잠금의 가치.
이전의 모든 작업에서 데이터가 변경되지 않았다고 가정하면 상태를 무시했습니다. 실제로, 데이터는 서비스 통화간에 변경되었을 수 있습니다. JSON과 관련된 이중성 관점은 우리에게 주를 관리하는 방법을 제공하여 우리에게 우리에게 제공합니다. “etag“효과적으로 우리가 낙관적 잠금에 사용할 수있는 버전. 이것은 가치 기반 동시성이라고도합니다. 다음 예는 이것을 보여줍니다.
예
데이터를 쿼리 할 수 있습니다 _etag 값:
SELECT JSON_SERIALIZE(d.data PRETTY) FROM department_details d WHERE d.data."_id" = 2;@unnest로 데이터를 평평하게합니다
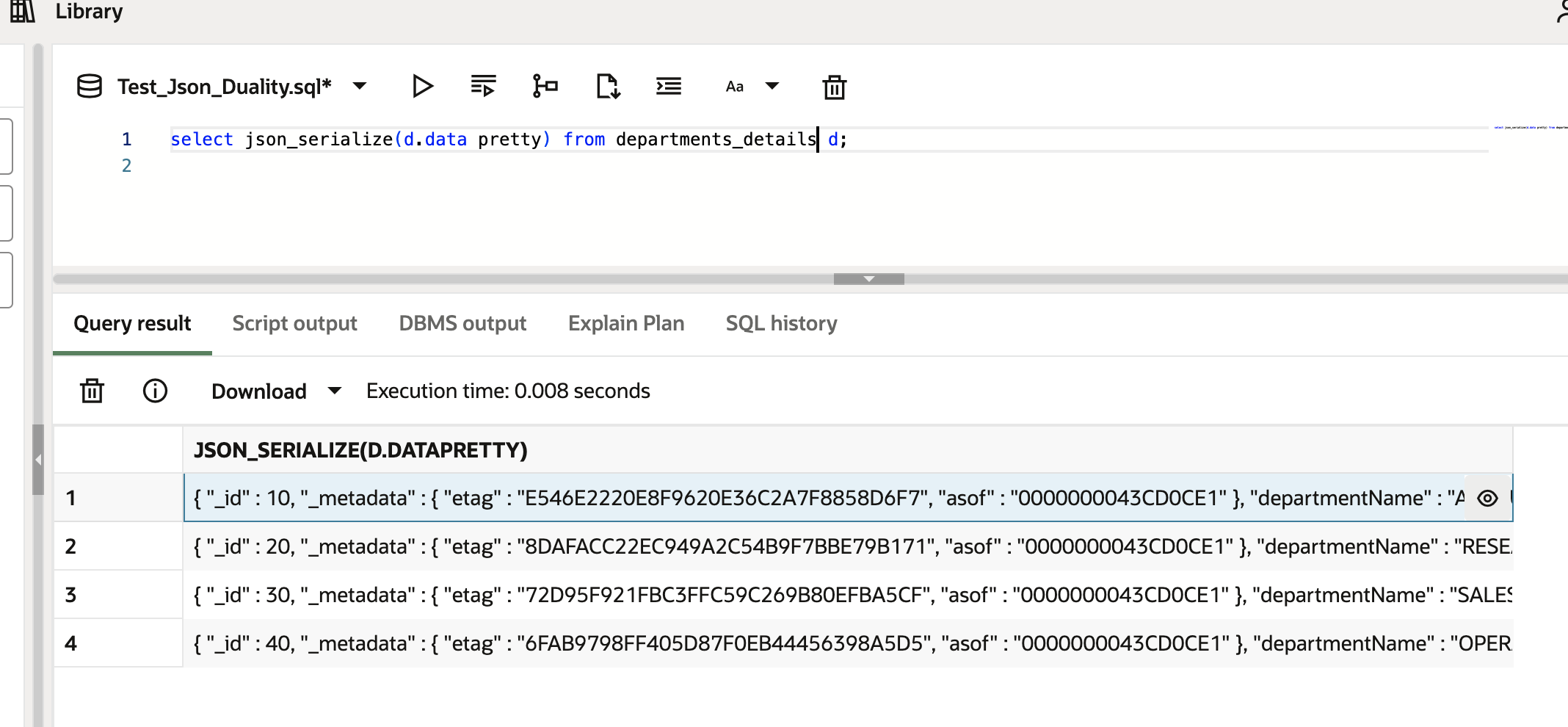
그만큼 UNNEST 키워드 (@unnest)이를 통해 스칼라 하위 퀘스트의 결과를 해제하여 평평한 문서를 생성 할 수 있습니다. 이 예에서 우리는 다음을 만듭니다 EMPLOYEES_DETAILS 평평한 문서에 직원 정보 및 각 직원에 대한 관련 부서 정보가 포함되어 있습니다. 주목하십시오 UNNEST 두 예에서 키워드.
평평한 JSON 문서를 결합 할 수 있습니다 employees 그리고 department 정보.
CREATE
OR
replace json relational duality VIEW employee_details AS
SELECT json { '_id': e.emp_id,
'employeeName': e.emp_name,
'role': e.ROLE,
'salary': e.salary,
unnest
(
SELECT json { 'departmentId': d.dept_id,
'departmentName': d.dept_name,
'location': d.location }
FROM departments d WITH
UPDATE
WHERE d.dept_id = e.dept_id ) }
FROM employees e WITH
INSERT
UPDATE
DELETE;평평한 뷰를 쿼리하십시오.
SELECT JSON_SERIALIZE(d.data PRETTY) FROM employee_details d;
set long 1000000 pagesize 1000 linesize 100
select json_serialize(d.data pretty) from employee_details d;
JSON_SERIALIZE(D.DATAPRETTY)
----------------------------------------------------------------------------------------------------
{
"_id" : 7369,
"_metadata" :
{
"etag" : "A63777A126E5F53961E8C4A16C266EBB",
"asof" : "00000000002F2825"
},
"employeeName" : "SMITH",
"job" : "CLERK",
"salary" : 800,
"departmentNumber" : 20,
"departmentName" : "RESEARCH",
"location" : "DALLAS"
}
{
"_id" : 7499,
"_metadata" :
{
"etag" : "9D9E402CAF3D10EF54D4247D73823D3F",
"asof" : "00000000002F2825"
},
"employeeName" : "ALLEN",
"job" : "SALESMAN",
"salary" : 1600,
"departmentNumber" : 30,
"departmentName" : "SALES",
"location" : "CHICAGO"
}
.
.
.
-- X rows selected.
결론
Oracle 23AI의 JSON 관계형 이중성은 최고의 관계 및 JSON 세계를 병합하여 데이터 처리를 향상시킵니다. 쿼리, 업데이트 또는 동시성 관리에 관계없이 개발자가 현대적이고 확장 가능한 응용 프로그램을 쉽게 구축 할 수 있습니다.













Post Comment