신경망 중량 양자화
-%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%96%91%EC%9E%90%ED%99%94-1_image_1.png?w=1920&resize=1920,998&ssl=1 "신경망 중량 양자화")
점점 더 큰 언어 모델과 복잡한 신경망의 시대에 모델 효율을 최적화하는 것이 가장 중요해졌습니다. 중량 양자화는 모델 크기를 줄이고 성능 저하없이 추론 속도를 향상시키는 데 중요한 기술로 두드러집니다. 이 안내서는 GPT-2를 실질적인 예로 사용하여 중량 양자화를 구현하고 이해하는 실습 접근법을 제공합니다.
학습 목표
- 중량 양자화의 기본 사항과 모델 최적화의 중요성을 이해하십시오.
- Absmax와 Zero-Point Quantization 기술의 차이점을 배우십시오.
- Pytorch를 사용하여 GPT-2에서 중량 양자화 방법을 구현하십시오.
- 메모리 효율, 추론 속도 및 정확도에 대한 양자화의 영향을 분석하십시오.
- 통찰력을 위해 히스토그램을 사용하여 정량화 된 중량 분포를 시각화합니다.
- 텍스트 생성 및 당황 메트릭을 통해 정량 후 모델 성능을 평가합니다.
- 자원으로 제한된 장치에 모델을 배포하기위한 양자화의 장점을 탐색하십시오.
이 기사는의 일부로 출판되었습니다 데이터 과학 블로그.
중량 양자화 기본 사항 이해
중량 양자화는 고정밀 부동산 중량 (일반적으로 32 비트)을 낮은 정밀 표현 (일반적으로 8 비트 정수)으로 변환합니다. 이 프로세스는 모델 성능을 보존하려고 시도하면서 모델 크기와 메모리 사용량을 크게 줄입니다. 주요 과제는 수치 정밀도를 줄이면서 모델 정확도를 유지하는 데 있습니다.
왜 양자화됩니까?
- 메모리 효율 : 정밀도를 32 비트에서 8 비트로 감소시키는 것은 이론적으로 모델 크기를 75% 줄일 수 있습니다.
- 더 빠른 추론 : 정수 작업은 일반적으로 부동 소수점 작업보다 빠릅니다
- 낮은 전력 소비 : 메모리 대역폭 감소 및 단순한 계산으로 에너지 절약으로 이어집니다.
- 배포 유연성 : 작은 모델은 자원으로 제한된 장치에 배포 될 수 있습니다
실제 구현
Absmax Quantization과 Zero-Point Quantization의 두 가지 인기있는 양자화 방법을 구현합시다.
환경 설정
먼저, 필요한 종속성으로 개발 환경을 설정할 것입니다.
import seaborn as sns
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
from copy import deepcopy
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as sns아래에서는 양자화 방법을 구현할 것입니다.
Absmax Quantization
Absmax Quantization 방법은 텐서의 최대 절대 값에 따라 가중치를 스케일링합니다.
# Define quantization functions
def absmax_quantize(X):
scale = 100 / torch.max(torch.abs(X)) # Adjusted scale
X_quant = (scale * X).round()
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequant이 방법은 다음과 같이 작동합니다.
- 중량 텐서에서 최대 절대 값을 찾습니다
- int8 범위 내에서 값에 맞게 스케일링 계수 계산
- 값을 스케일링하고 반올림합니다
- 양자화 된 버전 및 탈염 된 버전을 제공합니다
주요 장점 :
- 간단한 구현
- 큰 가치의 좋은 보존
- 주위의 대칭 양자화
제로 포인트 양자화
제로 포인트 양자화는 비대칭 분포를 더 잘 처리하기 위해 오프셋을 추가합니다.
def zeropoint_quantize(X):
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range
scale = 200 / x_range
zeropoint = (-scale * torch.min(X) - 128).round()
X_quant = torch.clip((X * scale + zeropoint).round(), -128, 127)
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequant산출:
Using device: cuda이 방법 :
- 전체 값을 계산합니다
- 스케일 및 제로 포인트 매개 변수를 결정합니다
- 스케일링 및 이동을 적용합니다
- int8 경계를 보장하기 위해 클립 값
이익:
- 비대칭 분포의 더 나은 취급
- 거의 0의 값의 표현 개선
- 종종 전반적인 정확도가 향상됩니다
모델을로드하고 준비합니다
이러한 양자화 방법을 실제 모델에 적용합시다. GPT-2를 예제로 사용할 것입니다.
# Load model and tokenizer
model_id = 'gpt2'
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Print model size
print(f"Model size: {model.get_memory_footprint():,} bytes")산출:
양자화 과정 : 가중치 및 모델
개별 가중치와 전체 모델 모두에 양자화 기술을 적용하는 데있어. 이 단계는 성능을 유지하면서 메모리 사용량과 계산 효율성을 줄입니다.
# Quantize and visualize weights
weights_abs_quant, _ = absmax_quantize(weights)
weights_zp_quant, _ = zeropoint_quantize(weights)
# Quantize the entire model
model_abs = deepcopy(model)
model_zp = deepcopy(model)
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.data)
param.data = dequantized
for param in model_zp.parameters():
_, dequantized = zeropoint_quantize(param.data)
param.data = dequantized양자 무게 분포 시각화
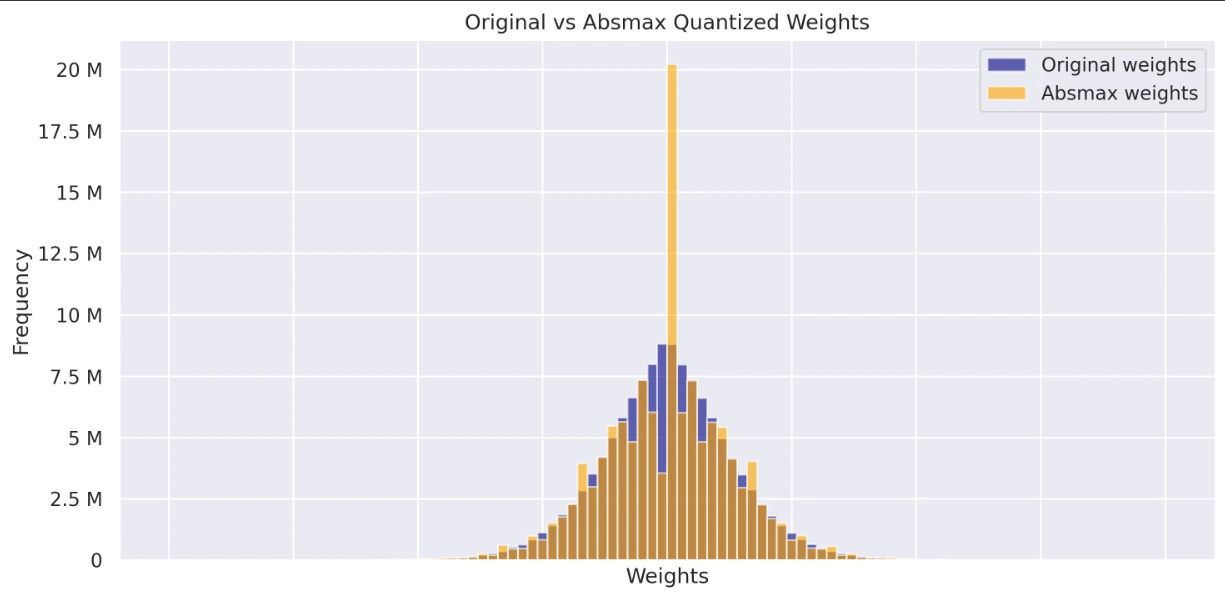
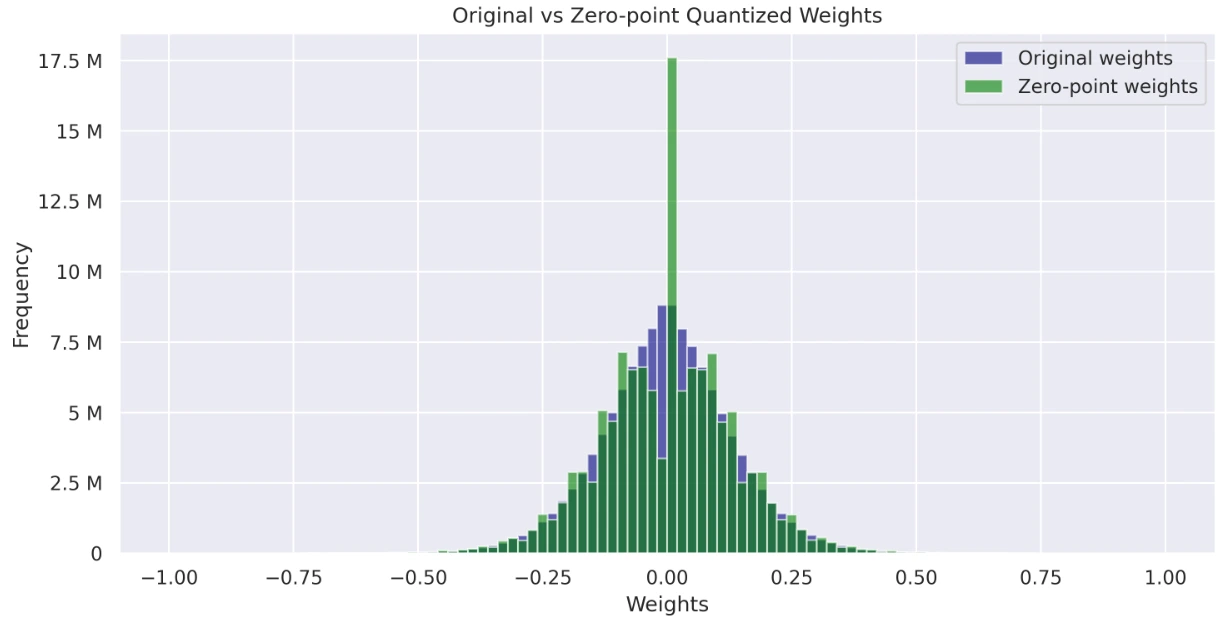
원본, Absmax Quantized 및 Zero-Point Quantized 모델의 중량 분포를 시각화하고 비교하십시오. 이 히스토그램은 양자화가 중량 값에 미치는 영향과 전체 분포에 대한 통찰력을 제공합니다.
# Visualize histograms of weights
def visualize_histograms(original_weights, absmax_weights, zp_weights):
sns.set_theme(style="darkgrid")
fig, axs = plt.subplots(2, figsize=(10, 10), dpi=300, sharex=True)
axs[0].hist(original_weights, bins=100, alpha=0.6, label="Original weights", color="navy", range=(-1, 1))
axs[0].hist(absmax_weights, bins=100, alpha=0.6, label="Absmax weights", color="orange", range=(-1, 1))
axs[1].hist(original_weights, bins=100, alpha=0.6, label="Original weights", color="navy", range=(-1, 1))
axs[1].hist(zp_weights, bins=100, alpha=0.6, label="Zero-point weights", color="green", range=(-1, 1))
for ax in axs:
ax.legend()
ax.set_xlabel('Weights')
ax.set_ylabel('Frequency')
ax.yaxis.set_major_formatter(ticker.EngFormatter())
axs[0].set_title('Original vs Absmax Quantized Weights')
axs[1].set_title('Original vs Zero-point Quantized Weights')
plt.tight_layout()
plt.show()
# Flatten weights for visualization
original_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model.parameters()])
absmax_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model_abs.parameters()])
zp_weights = np.concatenate([param.data.cpu().numpy().flatten() for param in model_zp.parameters()])
visualize_histograms(original_weights, absmax_weights, zp_weights)코드에는 포괄적 인 시각화 기능이 포함됩니다.
- 원래 가중치와 Absmax 가중치를 표시하는 그래프
- 원래 가중치와 제로 포인트 가중치를 표시하는 그래프
산출:
성능 평가
효율성과 정확성을 보장하기 위해서는 양자화가 모델 성능에 미치는 영향을 평가하는 것이 필수적입니다. 양자화 된 모델이 원본에 비해 얼마나 잘 수행되는지 측정 해 봅시다.
텍스트 생성
양자화 된 모델이 텍스트를 생성하는 방법을 살펴보고 출력 품질을 원래 모델의 예측과 비교하십시오.
def generate_text(model, input_text, max_length=50):
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
output = model.generate(inputs=input_ids,
max_length=max_length,
do_sample=True,
top_k=30,
pad_token_id=tokenizer.eos_token_id,
attention_mask=input_ids.new_ones(input_ids.shape))
return tokenizer.decode(output[0], skip_special_tokens=True)
# Generate text with original and quantized models
original_text = generate_text(model, "The future of AI is")
absmax_text = generate_text(model_abs, "The future of AI is")
zp_text = generate_text(model_zp, "The future of AI is")
print(f"Original model:\n{original_text}")
print("-" * 50)
print(f"Absmax model:\n{absmax_text}")
print("-" * 50)
print(f"Zeropoint model:\n{zp_text}")이 코드는 원본, “Absmax”양자화 된 모델 및 “Zeropoint”양자 모델의 세 가지 모델에서 텍스트 생산 출력을 비교합니다. Generate_Text 함수를 사용하여 입력 프롬프트를 기반으로 텍스트를 생성하여 최상위 k 값이 30 인 샘플링을 적용합니다. 마지막으로 세 가지 모델 모두에서 결과를 인쇄합니다.
산출:

# Perplexity evaluation
def calculate_perplexity(model, text):
encodings = tokenizer(text, return_tensors="pt").to(device)
input_ids = encodings.input_ids
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
return torch.exp(outputs.loss)
long_text = "Artificial intelligence is a transformative technology that is reshaping industries."
ppl_original = calculate_perplexity(model, long_text)
ppl_absmax = calculate_perplexity(model_abs, long_text)
ppl_zp = calculate_perplexity(model_zp, long_text)
print(f"\nPerplexity (Original): {ppl_original.item():.2f}")
print(f"Perplexity (Absmax): {ppl_absmax.item():.2f}")
print(f"Perplexity (Zero-point): {ppl_zp.item():.2f}")이 코드는 세 가지 모델을 사용하여 주어진 입력에 대한 당연 성 (모델이 텍스트를 얼마나 잘 예측하는지)를 계산합니다 : 원래 “absmax”정량화 및 “Zeropoint”정량화 된 모델. 당혹감이 낮 으면 성능이 향상됩니다. 비교를 위해 당황 점수를 인쇄합니다.
산출:

Colab 링크에 액세스 할 수 있습니다.
중량 양자화의 장점
아래에서 우리는 체중 양자화의 장점을 조사 할 것입니다.
- 메모리 효율 : 양자화는 모델 크기를 최대 75%까지 줄여 더 빠른 하중 및 추론을 가능하게합니다.
- 더 빠른 추론 : 정수 작업은 부동 소수점 작업보다 빠르기 때문에 더 빠른 모델 실행을 초래합니다.
- 낮은 전력 소비 : 메모리 대역폭이 줄어들고 단순화 된 계산은 에너지 절약으로 이어지며, 에지 장치 및 모바일 배포에 필수적입니다.
- 배포 유연성 : 소규모 모델은 제한된 리소스 (예 : 휴대폰, 임베디드 장치)를 사용하여 하드웨어에 더 쉽게 배포 할 수 있습니다.
- 최소 성능 저하 : 올바른 양자화 전략을 통해 모델은 정밀도 감소에도 불구하고 대부분의 정확도를 유지할 수 있습니다.
결론
중량 양자화는 특히 자원 제약 장치에 배치 할 때 큰 언어 모델의 효율성을 향상시키는 데 중요한 역할을합니다. 고정밀 가중치를 낮은 정밀 정수 표현으로 변환함으로써 모델의 성능에 심각하게 영향을 미치지 않으면 서 메모리 사용량을 크게 줄이고 추론 속도를 개선하며 전력 소비를 줄일 수 있습니다.
이 안내서에서, 우리는 ABSMAX Quantization 및 Zero-Point Quantization의 두 가지 인기있는 양자화 기술을 실질적인 예로 사용했습니다. 두 기술 모두 텍스트 생성 작업에서 높은 수준의 정확도를 유지하면서 모델의 메모리 발자국 및 계산 요구 사항을 줄이는 기능을 보여주었습니다. 그러나, 비대칭 접근법을 갖는 제로 포인트 양자화 방법은 일반적으로 비대칭 중량 분포에 대한 모델 정확도를 더 잘 보존하게 만들었다.
주요 테이크 아웃
- Absmax Quantization은 더 간단하고 대칭 중량 분포에 적합하지만 비대칭 분포를 제로 포인트 양자화만큼 효과적으로 캡처하지는 않습니다.
- 제로 포인트 양자화는 비대칭 분포를 처리하기위한 오프셋을 도입하여보다 유연한 접근 방식을 제공하며, 종종 더 나은 정확도와보다 효율적인 가중치 표현으로 이어집니다.
- 양자화는 계산 자원이 제한되는 실시간 응용 프로그램에 대형 모델을 배포하는 데 필수적입니다.
- 양자화 프로세스가 정밀도를 감소 시키지만 적절한 튜닝 및 양자화 전략으로 모델 성능을 원본에 가깝게 유지할 수 있습니다.
- 히스토그램과 같은 시각화 기술은 양자화가 모델 가중치에 미치는 영향과 텐서의 값 분포에 대한 통찰력을 제공 할 수 있습니다.
자주 묻는 질문
A. 무게 양자화는 성능을 유지하면서 메모리와 계산을 저장하기 위해 일반적으로 32 비트 부동산 지점 값 (예 : 8 비트 정수)으로 모델의 가중치의 정밀도를 감소시킵니다.
A. 양자화는 모델의 메모리 발자국과 추론 시간을 줄이지 만 정확도가 약간 저하 될 수 있습니다. 그러나 올바르게 수행하면 정확도 손실이 최소입니다.
A. 예, 언어 모델, 비전 모델 및 기타 딥 러닝 아키텍처를 포함한 모든 신경망 모델에 양자화를 적용 할 수 있습니다.
A. 모델의 가중치를 확장하고 반올림하기위한 함수를 만들어 양자화를 구현 한 다음 모든 매개 변수에 적용 할 수 있습니다. Pytorch와 같은 라이브러리는 일부 양자화 기술에 대한 기본 지원을 제공하지만 가이드에 표시된 것처럼 사용자 정의 구현은 유연성을 제공합니다.
A. 무게 양자화는 메모리 발자국과 계산을 줄이는 대형 모델에 가장 효과적입니다. 그러나 매우 작은 모델은 양자화로부터 많은 이점을 얻지 못할 수 있습니다.
이 기사에 표시된 미디어는 분석 Vidhya가 소유하지 않으며 저자의 재량에 따라 사용됩니다.
![]()
제 이름은 Nilesh Dwivedi 이며이 활기찬 블로거와 독자 커뮤니티에 참여하게되어 기쁩니다. 저는 현재 Btech의 첫해에 IIIT Dharwad의 데이터 과학 및 인공 지능을 전문으로하고 있습니다. 저는 기술과 데이터 과학에 열정을 가지고 있으며 더 많은 블로그를 작성하기를 기대합니다.













Post Comment