TreeLearn 및 Lidar 기반 포인트 클라우드를 사용한 정확한 산림 매핑

링크 표
초록 및 서론 1편
- 재료 및 방법
- 결과 및 토론
- 결론 및 참고자료
2 재료 및 방법
2.1 표시된 산림 데이터
TreeLearn 방법은 나무의 모든 부분에 대해 충분히 높은 스캔 해상도를 갖는 완전한 레이블이 지정된 숲 포인트 클라우드에 대해 학습될 수 있습니다. 이 기준을 충족하는 데이터를 찾기 위해 기존 문헌을 검색했습니다. 첫째, 최근에 발표된 FOR-instance 데이터 세트(Puliti et al., 2023b)가 있는데, 여기에는 트리 레이블과 세분화된 의미 레이블이 기존 작업의 포인트 클라우드에 수동으로 추가되었습니다. 이러한 포인트 클라우드는 UAV 레이저 스캐닝을 통해 캡처되었으며 노르웨이(NIBIO), 체코(CULS), 오스트리아(TU WIEN), 뉴질랜드(SCION) 및 호주(RMIT)에 위치한 다양한 산림 지역으로 구성됩니다. 또 다른 최근 연구에서는 Lidar360 소프트웨어(GreenValley International, 2022)를 사용하여 독일(L1W)에 위치한 산림 플롯에 대한 나무 레이블을 얻은 다음 수동으로 수정했습니다. 각 데이터 세트의 특성에 대한 요약은 표 1에서 확인할 수 있습니다. 보다 정확한 정보는 해당 간행물에서 확인할 수 있습니다.
\ 이러한 포인트 클라우드 외에도 품질 보증을 위해 수동으로 확인(WYTHAM, Calders et al., 2022) 또는 수정(LAUTx, Tockner et al., 2022)된 자동 분할 알고리즘으로 얻은 고품질 분할 트리로 구성된 두 개의 게시된 데이터 세트가 식별되었습니다. 라벨이 지정되지 않은 완전한 포인트 클라우드를 얻기 위해 각 저자에게 연락했습니다. 이러한 포인트 클라우드에는 나무가 아닌 포인트(예: 지하층 또는 지면에 속함)와 주석이 없는 포인트(즉, 나무에 속하지만 게시된 데이터세트에 주석이 추가되지 않은 포인트)가 추가로 포함됩니다. 예를 들어, 특정 나무에 명확하게 할당하기 어려운 나무 왕관의 일부 부분에는 주석이 추가되지 않았을 수 있습니다.
\ 전체 포인트 클라우드에 대한 레이블을 얻으려면 게시된 데이터 세트의 트리 레이블을 전파해야 하며 나머지 포인트는 “비 트리” 또는 “주석 없음” 클래스에 할당되어야 합니다. 이는 다음과 같이 수행되었습니다.
\
-
레이블이 지정되지 않은 숲 포인트 클라우드의 각 포인트에 대해 반경 0.1m 내의 가장 일반적인 나무 레이블이 할당되었습니다.
\
-
라벨이 지정되지 않은 나머지 포인트 중에서 트리가 아닌 포인트는 근접 기반 클러스터링을 사용하여 식별되었습니다. 서로 0.3m 거리 내에 있는 모든 포인트는 연결되었으며 가장 큰 연결된 구성 요소는 트리가 아닌 포인트로 표시되었습니다. 큰 그룹화 반경과 높은 해상도의 포인트 클라우드 덕분에 모든 지하 및 지상 포인트가 나무가 아닌 클래스에 추가되었습니다.
\
-
이 단계에서 아직 레이블이 지정되지 않은 포인트는 주석이 지정되지 않았으며 주석이 지정되지 않은 클래스에 할당된 트리 지점을 나타냅니다. 이 정보는 훈련 중에 이러한 사항을 무시하는 데 사용될 수 있습니다.
\
-
마지막으로 포인트 클라우드를 육안으로 검사하여 트리, 트리가 아닌 포인트, 주석이 없는 포인트로 적절하게 구분되어 있는지 확인했습니다. 나머지 오류는 가능한 범위 내에서 수동으로 수정되었습니다. 특히 Calders et al.의 원래 레이블 데이터에서는 하나의 큰 나무가 분할되지 않았습니다. (2022)이 추가되었고 Tockner et al. (2022)는 원래 레이블이 지정된 데이터에서 대략적으로만 분할되었기 때문에 수정되었습니다.
\ 주어진 데이터 세트의 경우 고품질 분할 레이블은 10m보다 큰 나무를 고려할 때만 보장되고 나머지는 나무가 아닌 것으로 할당됩니다. WYTHAM에서는 작은 나무가 일관되지 않게 표시됩니다. 즉 때로는 나무로, 때로는 나무가 아닌 것으로 표시됩니다. LAUTX에서는 작은 나무에는 심각한 품질 제한이 있습니다. 이러한 실수를 수정하는 것은 이 작업의 범위를 벗어났습니다. 따라서 여기서는 10m보다 큰 나무만 고려했습니다.
2.2 분할 방법
본 연구에 사용된 모델 프레임워크는 TreeLearn(Henrich et al., 2023)입니다. 인스턴스 분할을 위해 널리 사용되는 그룹화 기반 패러다임(Qi et al., 2019)을 사용합니다. 포인트 클라우드는 3D-UNet을 사용하여 처리되고 포인트별 의미론 및 오프셋 예측이 이어집니다. 의미론적 예측은 포인트를 트리 또는 비트리로 분류하는 데 사용됩니다. 오프셋 예측은 각 포인트가 속한 트리 기반으로 각 포인트를 이동하는 것을 목표로 합니다. 예측된 오프셋을 각 포인트에 적용한 후 밀도 기반 클러스터링을 사용하여 트리 인스턴스를 식별할 수 있습니다. 메모리 제한을 설명하기 위해 저자는 결과를 병합하는 슬라이딩 윈도우 접근 방식을 제안했습니다.
2.3 실험
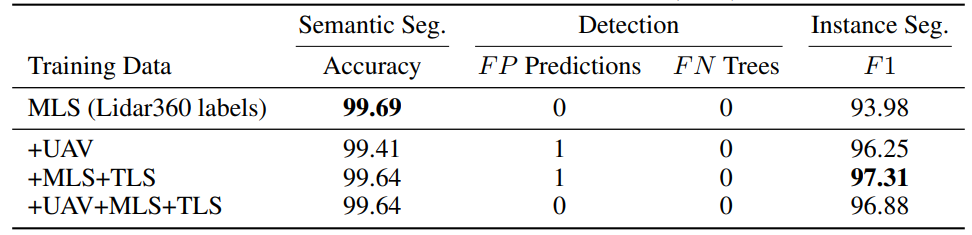
섹션 2.1에 제시된 레이블이 지정된 데이터를 사용하여 TreeLearn은 세 가지 조건에서 훈련되었습니다. (i) 첫 번째 조건에서는 UAV 데이터만 사용되었습니다(NIBIO, CULS, TU WIEN, SCION). 이러한 포인트 클라우드의 대부분은 침엽수가 우세한 숲에서 나옵니다. (ii) 두 번째 조건에서는 혼합림 또는 낙엽수림에서 나온 TLS 및 MLS 데이터(LAUTX, WYTHAM)만 사용되었습니다. (iii) 마지막으로 모든 데이터는 모델 훈련에 사용되었습니다. 세 가지 조건 모두에서 WYTHAM의 약 400그루의 나무를 포함하는 영역이 검증 세트로 사용되었습니다. 조건 (i)와 (ii)의 훈련 데이터에 있는 트리 수는 대략 동일합니다(765 대 762). 시험성능은 너도밤나무가 우점하는 낙엽수림인 L1W를 이용하여 평가하였다. 조건 (i)는 레이저 스캐닝 특성과 트리 구성이 L1W와 실질적으로 다르기 때문에 훈련 중에 도메인 외부 데이터를 사용하는 효과를 평가합니다. 조건 (ii)는 도메인 내 데이터를 나타냅니다. L1W에 대한 정량적 테스트 결과와 함께 저해상도 UAV 포인트 클라우드(RMIT)에 대한 정성적 테스트 결과도 제시된다.
\
\

\ L1W 데이터 세트의 성능은 Henrich et al.에 자세히 설명된 평가 프로토콜을 기반으로 평가됩니다. (2023). 먼저, 트리 탐지 성능은 위양성 및 위음성 예측 수로 측정됩니다. 트리 포인트와 비트리 포인트로의 의미론적 분할을 평가하기 위해 정확도가 계산됩니다. 인스턴스 분할 성능은 F1 점수를 사용하여 평가됩니다. 이는 참양성, 거짓양성, 거짓음성의 수를 기반으로 각 나무에 대해 개별적으로 계산된 다음 모든 나무에 걸쳐 평균을 냅니다.
\
:::정보
저자:
(1) 조나단 헨리히(Jonathan Henrich), 독일 괴팅겐 대학교 경제학부 통계 및 계량경제학 석좌 ([email protected])
(2) Jan van Delden, 독일 괴팅겐 대학교 컴퓨터 과학 연구소([email protected]).
:::
:::info 이 논문은 arxiv에서 사용 가능 CC by-SA 4.0 Deed(Attribution-Sharealike 4.0 International) 라이센스에 따라.
:::
\













Post Comment