AI는 벡터 데이터베이스를 충족합니다

키워드가 아니라 실제 의미와 같은 실제 의미로 인터넷을 검색 할 수 있기를 바랍니다. 그것은 AI가 벡터 데이터베이스를 팀으로 구성 할 때 일어나는 마법입니다.
전통적인 데이터베이스는 스프레드 시트와 같이 깨끗하고 구조화 된 물건에 적합합니다. 그러나 오늘날 우리가 만든 대부분의 데이터는? 지저분하고 구조화되지 않은 것 : 트윗, 사진, 음성 노트, 심지어 밈을 생각하십시오. 그것이 AI가 들어오는 곳입니다. 모든 혼란을 이해하는 것은 놀랍지 만, 그것을 저장하고 검색하려면 스마트 시스템이 필요합니다.
벡터 데이터베이스를 입력하십시오. 그들은 단어 일치하는 단어뿐만 아니라 의미 로이 새로운 종류의 검색을 처리하도록 만들어졌습니다.
이 게시물에서는이 강력한 듀오가 정보를 찾고 이해하는 방식을 어떻게 바꾸고 있는지 설명합니다. 우리는 실제 예제를 보여주고, 약간의 코드를 들여다 보며, 그것이 모두 함께 맞는지 살펴 보겠습니다.
그렇다면 벡터 데이터베이스는 정확히 무엇입니까?
지능 시대에, 우리는 많은 양의 복잡한 비무장 데이터 (레슨, 그림, 오디오, 비디오)를 생성하고 상호 작용합니다. 주로 일치하거나 미리 정해진 구조 (예 : SQL 테이블)를 기반으로하는 기존 데이터베이스 및 검색 방법은이 데이터의 의미와 참조를 이해하기 위해 노력합니다. 인공 지능 (AI)과 벡터 데이터베이스의 강력한 조합이 등장하는 곳입니다.
문제
키워드 대신 이데올로기 적 평등이나 의미를 기반으로 데이터를 어떻게 검색합니까? 예를 들어, 정확한 단어가 메일이 아니더라도 “아파트 생활을위한 최고의 개 품종은 작고 시원한 개에 적합하다”는 것을 어떻게 이해할 수 있습니까?
해결책
AI (임베딩 모델)
AI 모델, 특히 딥 러닝 모델 (예 : LLM 또는 레슨을위한 Sentence-Bart, 이미지/텍스트 클립)과 같은 특별한 사람들은 조밀 한 수치 표현으로 벡터 임베딩이라는 조밀 한 수치 표현으로 복잡한 데이터를 변경하는 법을 배웁니다. 이 벡터의 주요 특성은 비슷한 의미 나 특징을 가진 항목이 고차원 “벡터 공간”에 가깝게 서로 가깝게 매핑된다는 것입니다.
벡터 데이터베이스
이들은 고차원 벡터 임베딩을 명확하게 찾고, 저장하고, 효율적으로 색인하도록 설계된 특수 데이터베이스입니다. 그들은 투사 이웃 (ANN) 발견 (예 : HNSW, IVF)과 같은 알고리즘을 사용하여 주어진 쿼리 벡터 (가장 유사한)에 가장 가까운 벡터 (따라서 원래 데이터를 나타냄)를 사용하여 주어진 채석장 벡터입니다.
AI Vector DB 팀업 : 함께 플레이하는 방법
그렇다면이 태그 팀은 실제로 어떻게 작동합니까? 다음과 같이 생각하십시오.
- AI는 이해합니다: AI 모델은 “읽기”또는 “봅니다”데이터 (텍스트, 이미지 등).
- AI는 좌표를 만듭니다: AI는 이해를 바탕으로 벡터 임베딩을 생성합니다. 즉 개념지도에서 데이터의 의미를 정확히 찾아냅니다.
- 벡터 DB 매장: 벡터 데이터베이스는 이러한 좌표 (벡터)와 데이터의 ID를 가져 와서 저장하며 맵을 효율적으로 탐색하기 위해 초고속 바로 가기 (인덱스)를 구축합니다.
- 질문하십시오: 우리는 쿼리 (텍스트, 아마도 이미지 일 수도 있음)를 제공합니다.
- AI는 쿼리에 대한 좌표를받습니다: 같은 AI 모델은지도에서 쿼리의 좌표를 알아냅니다.
- 벡터 DB는 이웃을 찾습니다: 우리는 벡터 데이터베이스에게 “근처에있는 것 이것들 좌표? “데이터베이스는 빠른 단축키 (Ann 검색)를 사용하여 맵에서 밀리 초의 가장 가까운 점을 찾습니다.
- 관련 물건을 얻으십시오: 데이터베이스는 가장 가까운 항목의 ID를 알려줍니다.
이 팀 업이 왜 그렇게 중요한가?
- 의미를 얻습니다: ai 임베딩은 무엇을 포착합니다 수단사용 된 단어만이 아닙니다.
- 매우 빠른: 벡터 DBS는 수십억 개의 데이터 포인트가 있어도 유사한 항목을 엄청나게 빠르게 찾기 위해 구축되었습니다.
- 엄청난 양의 데이터를 처리합니다: 그들은 AI가 작동하는 거대한 복잡한 데이터 세트를 위해 설계되었습니다.
그래서 우리는 무엇을 할 수 있습니까? 하다 이것으로?
- 우리를 이해하는 검색: “실행을위한 편한 신발”을 검색하고 “조깅을위한 훌륭한 스니커즈”에 대한 결과를 얻는 것을 상상해보십시오. 시스템이 의지.
- 스팟 온 추천: Netflix 또는 Spotify가 다음에 우리가 무엇을 좋아하는지 알지 못하는 방법이 궁금하십니까? 그들은 종종 우리의 선호도 (벡터)를 영화 나 노래 (벡터)와 비교하여 훌륭한 경기를 찾습니다.
- 더 똑똑한 챗봇: 실제로 우리의 질문을 이해하고 지식 기반에서 관련 답변을 가져 오는 챗봇은 키워드뿐만 아니라 의미와 일치하기 때문입니다.
코드 몰래 엿보기 : 비슷한 물건 찾기 (개념적 예)
후드 아래에서 엿 보자. 우리는 이미 AI 모델을 사용하여 많은 문장에 대한 벡터 좌표를 만들고 벡터 데이터베이스 인덱스 (Pinecone)에 저장했다고 상상해보십시오. 이제 우리는 새로운 문장과 유사한 문장을 찾고 싶습니다.
# (Assuming setup with 'pinecone-client' and an embedding 'model') Our question, or "query"
query_sentence = "AI is amazing in the world"
# 1. Ask the AI model for the coordinates of our query
query_embedding = model.encode([query_sentence])[0].tolist()
# 2. Ask the Vector DB (index) to find the 2 closest neighbors
results = index.query(vector=query_embedding, top_k=2, include_metadata=True)
# 3. Look at what it found!
print(f"We asked about: \"{query_sentence}\"\n")
print("Here's what sounds similar:")
for match in results["matches"]:
original_text = match.get('metadata', {}).get('text', 'N/A') # Get the original text if stored
print(f" - Found: \"{original_text}\" (Similarity Score: {match['score']:.2f})") # Show score방금 무슨 일이 있었나요?
우리는 문장 ( “AI가 놀랍습니다 …”)을 벡터 좌표로 바꿨습니다. 그런 다음 벡터 데이터베이스에 좌표가 쿼리 좌표에 가장 가까운 두 개의 저장된 문장을 찾도록 요청했습니다. 데이터베이스는 그 문장을 반환했습니다 (아마도 “나는 인공 지능 기술을 좋아할 수도 있습니다”또는 “AI의 기능은 정말 믿어지지 않습니다”)와 함께 점수를 보여줍니다. 어떻게 비슷했습니다. 꽤 깔끔합니까? 공유 된 의미를 바탕으로 사물을 찾고 있습니다!
이것이 중요한 이유 : 오늘 우리가 사용할 수있는 것들
이미 일상적인 기술을 더 좋게 만들고 있습니다.
- 그냥 검색하십시오 얻는다 그것: “외부의 행복한 개 사진”을 검색하고 정확한 단어로 태그가없는 경우에도 멋진 사진을 찾으십시오. 시스템은 개념 공원에서 즐거운 강아지.
- 마술처럼 느껴지는 권장 사항: 우리가 가장 좋아하는 스트리밍 서비스 나 쇼핑 사이트는 어떻게 우리의 취향을 잘 알고 있습니까? 종종 그들은이 기술을 사용하여 우리의 선호도를 깊은 유사성을 기반으로 한 항목과 일치합니다.
- 발견 저것 사진 또는 비디오 클립: 파일 이름을 넘어서! 이름의 이름에 관계없이 해변 일몰으로 모든 사진을 찾는 것과 같이 미디어 라이브러리를 시각적으로 유사한 콘텐츠를 검색하십시오.
- 유용한 챗봇 및 Q & A: 챗봇이 의미 우리의 질문 뒤에 벡터로 저장된 관련 정보를 찾습니다.
- 발견 이상한 하나 밖으로:이 기술은 보안에도 좋습니다. 금융 거래와 같은 정상적인 패턴을 매핑함으로써 “의미 맵”에서 다른 모습을 보이는 비정상적인 활동 (잠재적 사기와 같은)을 즉시 발견 할 수 있습니다.
기본 여정 : 데이터가 있습니다
워크 플로우 다이어그램은 다음과 같습니다.
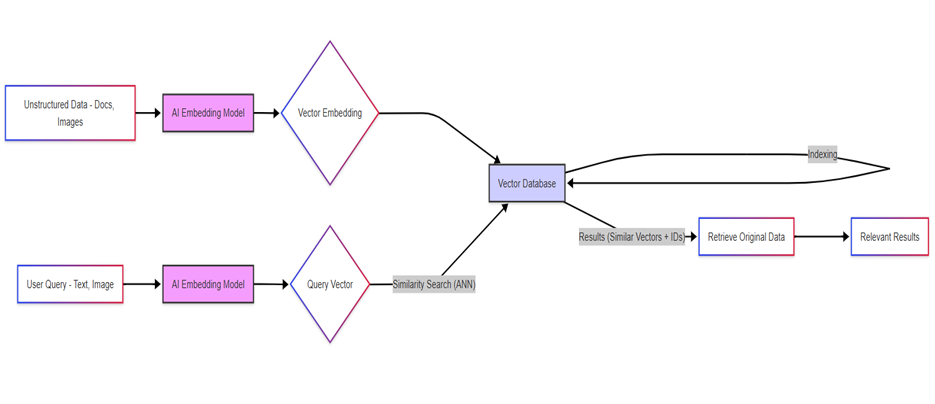
물건이 들어온다
원시 데이터 (텍스트, 사진, 오디오)가 시스템에 들어갑니다.
- AI는 그것을 알아냅니다: AI 모델은 데이터를보고 의미 기반 좌표 (벡터 임베딩)를 제공합니다.
- 좌표가 저장됩니다: 이러한 벡터 (및 원래 데이터로의 링크)는 벡터 데이터베이스에 저장되고 구성됩니다.
- 우리는 묻습니다: 우리는 쿼리를 입력하고 이미지 업로드 등을 입력합니다.
- 쿼리는 좌표를받습니다: 동일한 AI 모델은 쿼리에 자체 좌표를 제공합니다.
- 데이터베이스는 이웃을 찾습니다: 벡터 데이터베이스는 “맵”을 빠르게 검색하여 쿼리 좌표에 가장 가까운 좌표로 저장된 데이터를 찾습니다.
- 비슷한 물건이 돌아 왔습니다: 데이터베이스는 가장 유사한 항목을 가리 킵니다.
- 원래 데이터를 가져 왔습니다: 시스템은 데이터베이스의 포인터를 사용하여 실제 텍스트, 이미지 또는 제품 정보를 가져옵니다.
- 결과가 전달되었습니다: 우리는 관련 정보를 얻습니다!
실제 예 : 쇼핑 사이트
우리는 온라인 상점을 탐색 할 때, 멋진 운동화 한 켤레를 클릭하고, 즉시 제안을 보았습니다. 다른 비슷한 신발? 그것은 종종 직장에서 AI + 벡터 DBS입니다!
작동 방식 (비하인드 무대)
- 준비 작업 (사전 수행): 매장은 AI 모델을 사용하여 설명, 기능, 아마도 그림을 기반으로 모든 단일 제품의 벡터 “좌표”를 만듭니다. 이 좌표는 모두 벡터 데이터베이스에 저장됩니다.
- 방문 (실시간으로 발생):
- 우리는 그 빨간 운동화를 클릭합니다.
- 웹 사이트는 사전 계산 된 좌표를 즉시 가져옵니다 그 특정 신발.
- 벡터 데이터베이스에게 다음과 같이 묻습니다. “빠른! 이에 가까운 좌표가있는 다른 신발을 찾으십시오!”
- 벡터 DB는 초고속 검색을 수행하고 가장 유사한 신발 (파란색 트레일 러너, 가벼운 마라톤 신발 등)의 ID를 반환합니다.
- 웹 사이트는 비슷한 신발의 사진과 가격을 가져옵니다.
- 팔! 그들은 우리 페이지에 “우리가 좋아할 수도 있습니다”아래에 나타납니다.
원활하게 느껴지지만,이 영리한 기술은 깊은 유사성을 기반으로 관련 제안을하는 것이 우리가 실제로 좋아할 수있는 제품을 발견하는 데 도움이됩니다.
결론
AI 및 Vector 데이터베이스를 구성하는 것은 큰 도약입니다. 간단한 키워드 검색을 넘어 정보를 찾아서 진정으로 정보를 찾을 수 있습니다. 수단. 이것은 더 똑똑한 검색 엔진, 심령을 느끼는 추천 시스템 및 우리를 더 잘 이해하는 수많은 다른 응용 프로그램에 구동됩니다.
일이 여전히 사용되고 있습니다 (예 : 더 빠르고 저렴하게 만들기 위해). 실수는 없습니다.이 조합은 우리가 정보와 상호 작용하는 방식이 독창적이되고 있습니다. 우리가 앱을 만들거나 기술의 미래에 대해 열망하든, AI 및 벡터 데이터베이스가 어떻게 작동하는지 이해하더라도 빠른 지능 세계를 탐색하는 것이 중요합니다. 그것에 많이 볼 준비를하십시오!






: 아우라 카버부터 아우라 잉크까지")





Post Comment