AI 지원 인프라 설계: 최신 데이터 센터에 실제로 필요한 것

\ 지난 한 해 동안 컴퓨팅에 관한 모든 대화는 GPU, 모델 크기 및 훈련 실행을 중심으로 진행된 것으로 보입니다. 그러나 그 모든 과대광고 이면에는 훨씬 덜 화려하고 훨씬 더 고통스러운 것이 숨어 있습니다. 바로 AI 밀도 인프라를 구축하고 운영하는 물리적 현실입니다.
많은 조직에서는 이를 어려운 방법으로 발견하고 있습니다. 가속기 랙을 구입할 수 있지만 전체 전력, 냉각 및 네트워킹 스택이 준비되지 않으면 이러한 상자는 매우 비싼 공간 히터로 변합니다. 소프트웨어 문제 때문이 아니라 데이터 센터가 현재 세대 가속기의 열 및 전기적 설치 공간에 맞게 설계되지 않았기 때문에 배포가 몇 주 동안 중단되는 것을 보았습니다.
이 기사는 공급업체가 게시하는 화려한 다이어그램이 아니라 실무자가 실제로 다루는 엔지니어링 제약 조건이 아닌 AI 인프라 뒤에 있는 “실제 내용”을 설명하려는 시도입니다.
AI 워크로드가 기존 데이터센터를 파괴하는 이유
예를 들어 10~15kW의 전력을 소비하는 일반적인 기업용 랙은 꽤 예측 가능한 열 프로필을 가지고 있습니다. 서버 사용량이 많더라도 공기 흐름, PDU 및 차단기가 한계에 도달하는 경우는 거의 없습니다.
액셀러레이터 랙은 완전히 다른 동물입니다.
- 랙당 40~60kW가 점차 일반화되고 있습니다.
- ~35kW 이상에서는 액체 냉각이 필수가 됩니다.
- 전통적인 냉기 통로/열기 통로 디자인은 GPU 열에 영향을 받습니다.
조직에서는 AI 랙을 기존 행에 “그냥 놓기만 하면” 된다고 가정하는 경우가 많습니다. 현실: 일반적으로 유틸리티에서 랙 매니폴드까지 전체 배전 경로를 재구성해야 합니다.
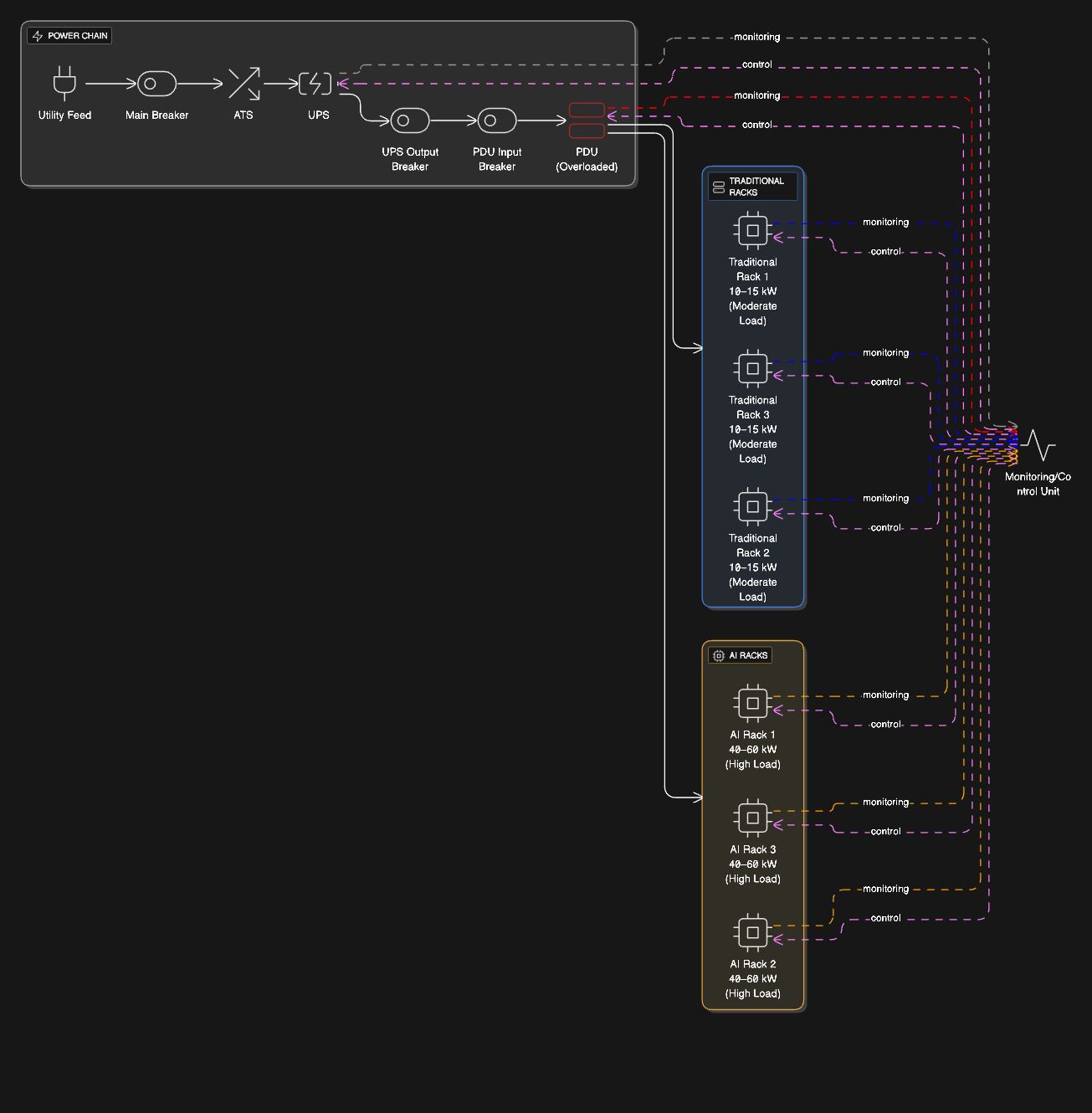
전력이 첫 번째 제약이 됨(GPU 아님)
8~16개의 가속기로 구성된 단일 랙은 5~6개의 기존 랙을 결합한 것보다 더 지속적인 전력을 쉽게 끌어옵니다. 그리고 CPU 워크로드와 달리 AI 워크로드는 긴 창, 몇 시간, 때로는 며칠 동안 높은 활용도로 실행됩니다.
이러한 지속적인 로드는 일반 엔터프라이즈 시스템이 숨길 수 있는 약점을 드러냅니다.
- 90% 이상의 지속 부하에서 실행되도록 의도되지 않은 UPS 세그먼트
- 기술적으로 전류량을 “지원”하지만 한계에 가깝게 뜨거워지는 PDU
- 열 스트레스로 인한 차단기 용량 감소
- 모든 것이 로드되면 실제로 중복되지 않는 중복 경로
단일 PDU 또는 UPS 세그먼트에 실수로 과부하가 걸리는 AI 배포의 수는 놀라울 정도로 높습니다.
\ \
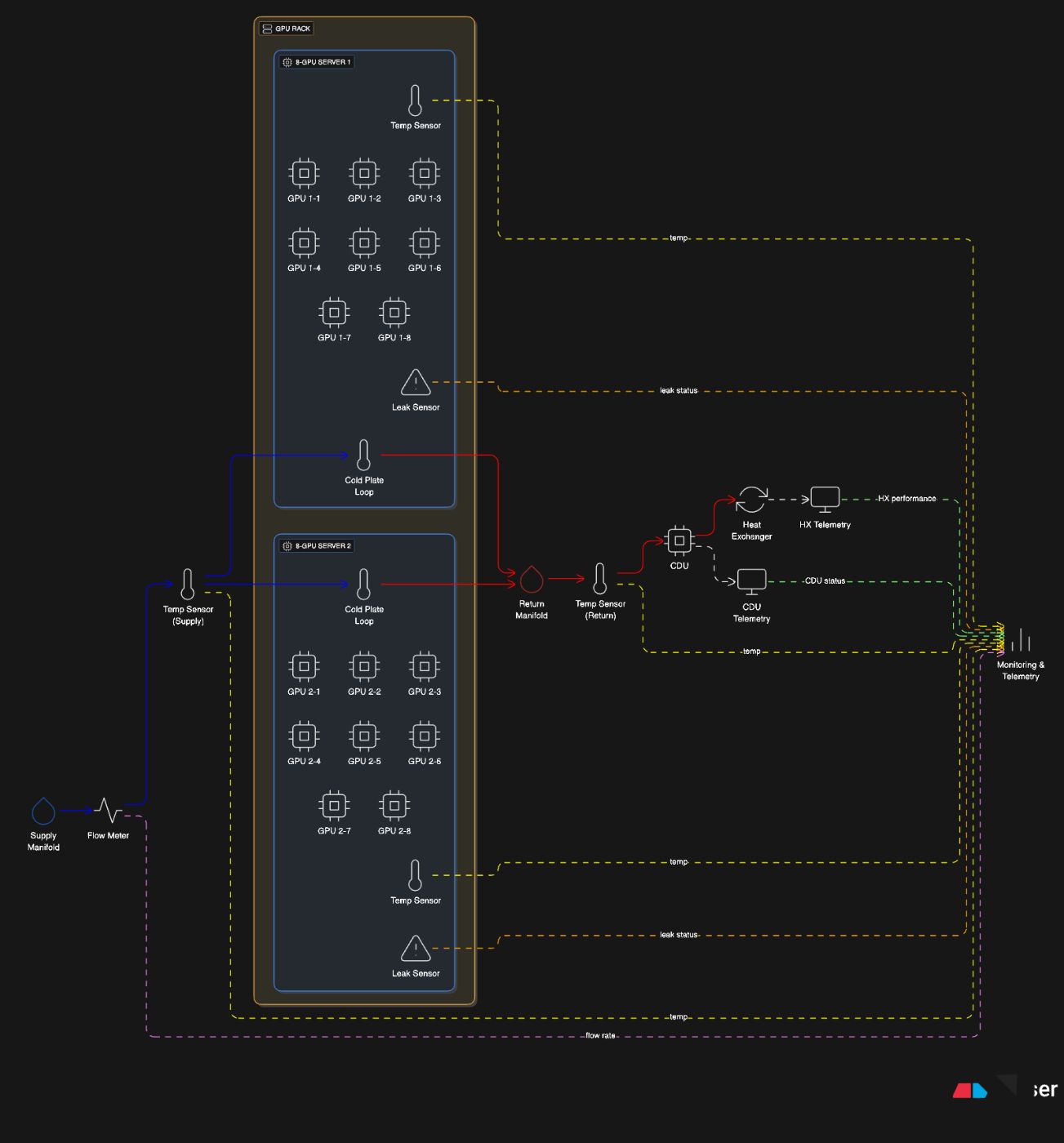
냉각: 아무도 이야기하고 싶지 않은 부분
랙이 40kW를 넘으면 기본적으로 공기 냉각이 포기됩니다. 실제로는 직접 칩 냉각판CDU(냉각수 분배 장치), 열 교환기 및 원격 측정이 지원됩니다.
AI 인프라의 이 부분은 기존 IT보다 산업 공학에 더 가깝습니다.
- 절삭유 공급 및 회수 라인
- 유량계 및 누출 감지
- 랙당 매니폴드
- GPU 루프를 공급하는 랙 수준 CDU
- 여러 지점에서 온도 변화 모니터링
그리고 전력 시스템과 달리 냉각 문제는 갑자기 나타나는 경향이 있습니다. 냉각수 라인의 작은 기포로 인해 1분 이내에 온도가 급등할 수 있습니다.
\
네트워킹: 훈련 클러스터 뒤에 숨겨진 복잡성
사람들은 GPU 상호 연결(NVLink, xGMI, Infinity Fabric)에 대해 많이 이야기하지만 몇 개의 노드를 넘어서면 네트워크 패브릭이 실제 제어 지점이 됩니다.
대부분의 GPU 클러스터에서:
- 훈련 트래픽은 동서로 무겁습니다.
- 무손실 또는 거의 무손실 패브릭이 필요합니다. (RoCEv2 또는 IB).
- 스위치 버퍼링 및 QoS 설정은 원시 대역폭보다 더 중요합니다.
- 초과 구독은 다중 노드 작업의 조용한 살인자입니다.
좋은 직물은 가격이 비싸고 운영상 취약합니다. 그러나 잘못된 패브릭은 디버깅이 거의 불가능한 간헐적인 학습 속도 저하를 유발합니다.
하나의 포드 이상으로 확장
실제 AI 배포는 “포드” 단위로 확장됩니다. 즉, 128, 256 또는 512개의 GPU가 긴밀하게 상호 연결됩니다. 포드를 함께 연결하면 네트워크 섬이라는 새로운 문제가 발생합니다.
확장할 수 있지만 포드 간 패브릭을 신중하게 엔지니어링하지 않으면 교육 워크로드가 소수의 업링크에서 병목 현상이 발생하게 됩니다.
이것이 바로 많은 조직이 두 번째 벽에 부딪히는 지점입니다. “1개의 포드가 작동함”에서 “3개의 포드가 하나의 클러스터로 작동”으로의 점프는 선형적이지 않습니다. 복잡도는 기하급수적에 가깝습니다.
AI 인프라 구축팀을 위한 실무적 조언
첫 번째 또는 두 번째 AI 밀도 배포를 설계하는 경우 고통스러운 경험에서 나온 몇 가지 지침은 다음과 같습니다.
- 동일한 PDU 세그먼트에 AI 랙과 기존 랙을 혼합하지 마십시오.
- 항상 냉각 용량을 20~25% 정도 늘리십시오. 당신은 그것이 필요합니다.
- 꼭 필요한 경우가 아니면 포드 간 네트워크 종속성을 피하세요.
- 하드웨어를 배포하기 전에 모니터링을 배포하세요.
- 환경이 “준비”되었다고 선언하기 전에 실제 GPU 로드로 스트레스 테스트를 실행하십시오.
모든 표준 승인 테스트를 통과한 시설이 실제 교육 실행을 시작한 지 45분 이내에 실패하는 것을 보았습니다.
최종 생각
매주 새로운 AI, 새로운 모델, 새로운 프레임워크, 새로운 논문 등 소프트웨어에 대한 흥미로움에 쉽게 빠져들 수 있습니다. 그러나 이 모든 것 아래에 있는 물리적 계층은 이러한 시스템이 대규모로 존재할 수 있도록 해줍니다.
AI 인프라를 구축하고 있다면 실시간으로 재창조되는 분야의 일부가 되는 것입니다. 오늘날의 대화는 혼란스럽고 실험적이며 알려지지 않은 내용으로 가득 찬 초기 클라우드 컴퓨팅과 매우 흡사합니다. 그러나 물리적 엔지니어링을 진지하게 받아들이는 팀이 실제로 제품을 출시하는 팀입니다.
\ \ \






: 아우라 카버부터 아우라 잉크까지")





Post Comment