AWS에서 확장 가능한 ML 파이프 라인 및 API 구축

머신 러닝 (ML) 및 인공 지능 (AI) 분야에서 빠른 발전으로 생산 환경에서 AI/ML 모델을 효율적으로 배포하는 것이 중요합니다.
이 블로그 게시물에서는 엔드 투 엔드 ML 파이프 라인에 대해 설명합니다 AWS SAGEMAKER 이는 서버리스 컴퓨팅, 이벤트 트리거 기반 데이터 처리 및 외부 API 통합을 활용합니다. 아키텍처 다운 스트림은 확장 성, 비용 효율성 및 실시간을 보장합니다 응용 프로그램에 대한 액세스.
이 블로그에서는 아키텍처를 살펴보고 설계 결정을 설명 하며이 시스템을 구축하는 데 사용되는 주요 AWS 서비스를 검토합니다.
아키텍처 개요
AWS 기반 ML 파이프 라인은 모델 실행, 데이터 저장, 처리 및 API 노출을 수행하기 위해 서로 완벽하게 통신하는 여러 구성 요소로 구성됩니다. 워크 플로에는 다음이 포함됩니다.
- AWS SAGEMAKER의 ML 모델 실행
- AWS S3, DynamoDB 및 Snowflake에 데이터를 저장합니다
- AWS Lambda 및 AWS 접착제를 사용한 이벤트 기반 처리
- AWS Lambda 및 Application Load Balancer와 실시간 API 통합
- AWS Route 53을 통해 응용 프로그램으로 트래픽을 라우팅합니다
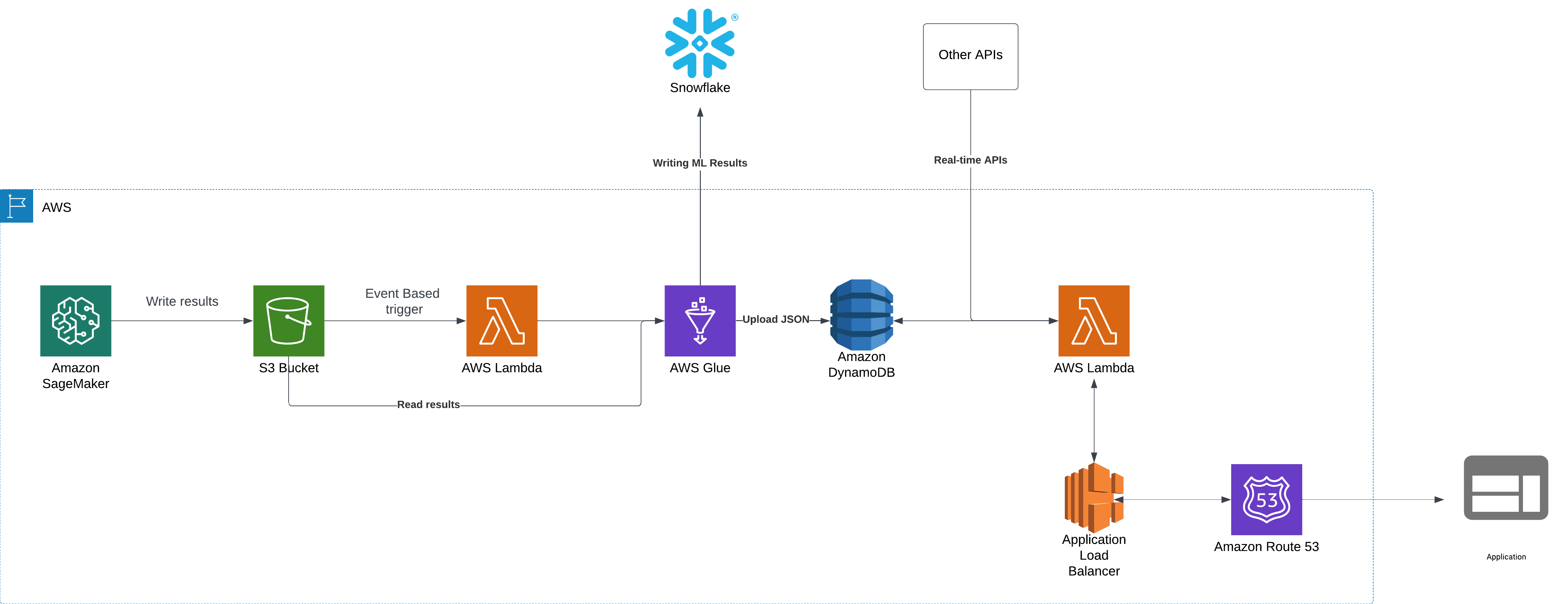
1 단계 : AWS SAGEMAKER에서 ML 모델 실행
시스템의 주요 구성 요소는 예측을 생성하기 위해 정기적으로 AWS Sagemaker에서 실행되는 ML 모델입니다. 이것을 배치 처리라고도합니다.
Sagemaker 파이프 라인 :
- 전처리 데이터와 이전 실행 결과를 사용합니다.
- 추론에 ML 알고리즘을 적용합니다.
- JSON 및 DELTA 형식의 출력을 S3 버킷에 씁니다.
JSON 및 DELTA 형식으로 데이터를 저장하는 이유?
- JSON은 가볍고 실시간 쿼리를 위해 AWS DynamoDB로 쉽게 소비 할 수 있습니다.
- 델타 형식을 사용하면 분석 및보고를 위해 효율적인 데이터를 눈송이로로드 할 수 있습니다.
2 단계 : 이벤트 기반 데이터 처리 및 스토리지
Sagemaker가 출력을 S3 버킷에 쓰면 이벤트 기반 트리거가 다음 단계를 자동으로 실행합니다.
- S3 이벤트 알림은 새로운 “완료된”파일이 해당 S3 위치에서 생성되는 즉시 트리거가 설정된 AWS Lambda 함수를 호출합니다.
- Lambda 기능은 AWS 접착제 작업을 호출합니다.
- JSON 데이터를 S3 위치에서 DynamODB로 처리하고로드합니다.
- 델타 데이터를 눈송이에 복사합니다.
데이터 수집에 AWS 접착제를 사용하는 이유는 무엇입니까??
- AWS Lambda의 최대 타임 아웃은 15 분입니다.
- 엄청난 양의 데이터 처리 및 업로드에 15 분 이상이 걸릴 수 있습니다.
- 접착제 ETL 변환은 구조적이고 깨끗한 데이터 수집이 보장되도록합니다.
3 단계 : API 처리 및 실시간 액세스
이제 데이터가 저장되었습니다 dynamodb 외부 응용 프로그램에 의해 액세스해야합니다. API를 사용하여 수행됩니다. AWS Lambda 기능을 사용하여 API 코드를 호스팅 할 수 있습니다.
- 응용 프로그램이 요청을 할 때 API Lambda 기능이 호출됩니다.
- API Lambda 기능 :
- 최신 ML 모델 결과로 DynamoDB를 쿼리합니다.
- 실시간 API (타사 서비스)와 통합하여 결과를 향상시킵니다.
- 이 모든 정보를 처리하고 API 응답을 생성합니다.
4 단계 : 애플리케이션 부하 밸런서 (ALB)를 사용한 API 노출
API 트래픽을 처리하려면 Lambda 기능이 AWS 애플리케이션로드 밸런서 (장백의).
애플리케이션로드 밸런서를 사용하는 이유는 무엇입니까??
- Alb는 트래픽을 관련 Lambda 기능으로 향합니다.
- API 요청 수에 따라 자동 가용성을 보장합니다.
- 여러 Lambda 인스턴스에서 트래픽을 효율적으로 배포합니다.
- 인증 및 요청 필터링을 수행하여 API 엔드 포인트를 보호합니다.
5 단계 : Route 53을 사용하여 API 호출 라우팅
우리는 AWS Route 53을 ALB와 통합하여 일관된 API 엔드 포인트를 얻습니다.
- Route 53은 도메인 이름 해상도를 처리하여 응용 프로그램이 API에 쉽게 연결할 수 있는지 확인합니다.
- 또한 사용자 정의 도메인 매핑을 지원하므로 다른 팀이 ALB 엔드 포인트에 직접 액세스하는 대신 사용자 친화적 인 API URL을 사용할 수 있습니다.
- API Lambda가 여러 지역에 배치 된 경우, Route 53은 트래픽을 효율적으로 라우팅하도록 구성하여 교대 기간 동안에도 신뢰성과 장애가를 보장 할 수 있습니다.
이 아키텍처의 가장 중요한 기능
- 확장 성 – Sagemaker, Lambda, Glue 및 DynamoDB 핸들과 같은 AWS 서비스
- 비용 최적화 -주문형 DynamoDB, Serverless Lambda 및 이벤트 기반 처리 사용은 효율적인 리소스 활용을 보장합니다.
- 실시간 처리 -LATENCH API로 ML 출력에 대한 실시간 액세스 제공
- 원활한 통합 -다른 실시간 API와의 통합을 지원하여 결과를 향상시킵니다.
- 교차 팀 협업 – Snowflake로 데이터를 내보내는 것은 비즈니스 및 기타 팀이 ML 예측에 대한 분석을 실행할 수 있도록 도와줍니다.
향후 개선 및 고려 사항
- 스트리밍 처리 -실시간 데이터 처리를 위해 배치 흐름을 Kafka 또는 Kinesis로 교체합니다.
- 자동화 된 모델 재교육 – 자동화 된 모델 재교육을 위해 Sagemaker 파이프 라인을 사용하십시오.
결론
이 AWS 기반 ML 아키텍처는 ML 모델을 실행하고 예측을 생성하며 실시간 API 응답을 제공하기위한 확장 가능하고 자동 및 효율적인 파이프 라인을 제공합니다. Sagemaker, Lambda, Glue, Dynamodb, Alb 및 Route 53과 같은 AWS 서비스를 활용함으로써 시스템은 다운 스트림 애플리케이션에 대한 비용 효율성, 고성능 및 실시간 데이터 가용성을 보장합니다.
당신의 생각을 듣고 싶습니다!









: 아우라 카버부터 아우라 잉크까지")



Post Comment