Python으로 Amazon 제품 리뷰를 스크랩하십시오

Amazon은 웹에서 다양한 형식으로 사용할 수있는 많은 양의 데이터가있는 잘 알려진 전자 상거래 플랫폼입니다. 이 데이터는 특히 다른 공급 업체가 제공하는 제품의 품질을 이해하기 위해 제품 리뷰를 분석하여 비즈니스 통찰력을 얻는 데 매우 중요합니다.
이 안내서에서는 특정 제품의 Amazon 리뷰를 추출하여 Excel 또는 CSV 형식으로 저장하기위한 웹 스크래핑 단계를 살펴 보겠습니다. 온라인으로 정보를 수동으로 복사하는 것은 지루할 수 있으므로 아마존의 리뷰를 긁는 데 중점을 둡니다. 이 실습 경험은 웹 스크래핑 기술에 대한 실질적인 이해를 향상시킬 것입니다.
전제 조건
시작하기 전에 시스템에 Python이 설치되어 있는지 확인하십시오. 이 링크에서 그렇게 할 수 있습니다. 프로세스는 매우 간단합니다. 다른 응용 프로그램을 설치하는 것처럼 설치하십시오.
이제 모든 것이 설정되었으므로 진행합시다.
Python을 사용하여 Amazon 리뷰를 긁어내는 방법
이 링크를 통해 Anaconda를 설치하십시오. 설치하는 동안 기본 설정을 따라야합니다. 더 많은 지침을 보려면이 비디오를 볼 수 있습니다.
https://www.youtube.com/watch?v=wuebzt43jyy
우리는 다양한 IDE를 사용할 수 있지만 초보자 친화적으로 유지하기 위해 Anaconda의 Jupyter Notebook부터 시작하겠습니다. 위의 링크 된 비디오를보고 소프트웨어에 대해 이해하고 익숙해 질 수 있습니다.
웹 스크래핑 Amazon 리뷰 단계
a 새로운 노트북 그리고 그것을 저장하십시오.
1 단계 : 필요한 모듈을 가져옵니다
다음 코드를 사용하여 필요한 모든 모듈 가져 오기 시작하겠습니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd2 단계 : 헤더 정의
IP가 차단되지 않도록 사용자 정의 헤더를 정의하십시오. 교체 할 수 있습니다 User-agent Google에서 “내 사용자 에이전트”를 검색하여 찾을 수있는 사용자 에이전트와 함께 가치가 있습니다.
custom_headers = {
"Accept-language": "en-GB,en;q=0.9",
"User-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1
Safari/605.1.15",
}3 단계 : 웹 페이지를 가져옵니다
파이썬 함수를 만들려면 웹 페이지를 가져오고 오류를 확인한 다음 BeautifulSoup 객체를 반환하여 추가 처리를합니다.
# Function to fetch the webpage and return a BeautifulSoup object
def fetch_webpage(url):
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Error in fetching webpage")
exit(-1)
page_soup = BeautifulSoup(response.text, "lxml")
return page_soup4 단계 : 검토 추출
요소를 찾으십시오 element and attribute 우리는 데이터를 추출하고자합니다. div 및 속성을 선택하여 extract_reviews 변하기 쉬운. 웹 페이지에서 리뷰 관련 요소를 식별하지만 아직 실제 검토 내용을 추출하지 않습니다. 이러한 요소에서 관련 정보를 추출하려면 코드를 추가해야합니다 (예 : 텍스트 검토, 등급 등).
# Function to extract reviews from the webpage
def extract_reviews(page_soup):
review_blocks = page_soup.select('div[data-hook="review"]')
reviews_list = []5 단계 : 프로세스 검토 데이터
아래 코드는 각 검토 요소를 처리하고 고객의 이름을 추출하고 (사용 가능한 경우) customer 변하기 쉬운. 아니오 customer 정보가 발견됩니다. customer 남아 있지 않습니다.
for review in review_blocks:
author_element = review.select_one('span.a-profile-name')
customer = author_element.text if author_element else None
rating_element = review.select_one('i.review-rating')
customer_rating = rating_element.text.replace("out of 5 stars", "") if rating_element else None
title_element = review.select_one('a[data-hook="review-title"]')
review_title = title_element.text.split('stars\n', 1)[-1].strip() if title_element else None
content_element = review.select_one('span[data-hook="review-body"]')
review_content = content_element.text.strip() if content_element else None
date_element = review.select_one('span[data-hook="review-date"]')
review_date = date_element.text.replace("Reviewed in the United States on ", "").strip() if date_element else None
image_element = review.select_one('img.review-image-tile')
image_url = image_element.attrs["src"] if image_element else None6 단계 : 프로세스 긁힌 검토
이 기능의 목적은 긁힌 검토를 처리하는 것입니다. 검토와 관련된 다양한 매개 변수가 필요합니다 (예 : customer,,, customer_rating,,, review_title,,, review_content,,, review_date및 이미지 URL) 및 함수는 처리 된 리뷰 목록을 반환합니다.
review_data = {
"customer": customer,
"customer_rating": customer_rating,
"review_title": review_title,
"review_content": review_content,
"review_date": review_date,
"image_url": image_url
}
reviews_list.append(review_data)
return reviews_list7 단계 : 검토 URL 초기화
이제 초기화합시다 search_url Amazon Product Review Page URL이있는 변수.
def main():
review_page_url = "
reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
page_soup = fetch_webpage(review_page_url)
scraped_reviews = extract_reviews(page_soup)8 단계 : 스크랩 된 데이터를 확인하십시오
이제 검증 목적으로 인쇄 (“스크랩 된 데이터 :”, 데이터) 스크랩 된 검토 데이터 (데이터 변수에 저장)를 콘솔에 긁어 봅시다.
# Print the scraped data to verify
print("Scraped Data:", scraped_reviews)9 단계 : 데이터 프레임을 만듭니다
다음으로 데이터에서 데이터 프레임을 작성하여 데이터를 표 형식으로 구성하는 데 도움이됩니다.
# create a DataFrame and export it to a CSV file
reviews_df = pd.DataFrame(data=scraped_reviews)10 단계 : 데이터 프레임을 CSV로 내 보냅니다
이제 데이터 프레임을 현재 작업 디렉토리의 CSV 파일로 내보내십시오.
reviews_df.to_csv("reviews.csv", index=False)
print("CSV file has been created.")11 단계 : 독립형 실행 확인
아래 코드 구성은 보호 측정으로 작용합니다. 스크립트가 다른 스크립트로 모듈로 가져 오지 않고 독립형 프로그램으로 직접 실행되는 경우에만 특정 코드가 실행되도록합니다.
# Ensuring the script runs only when executed directly
if __name__ == '__main__':
main()결과
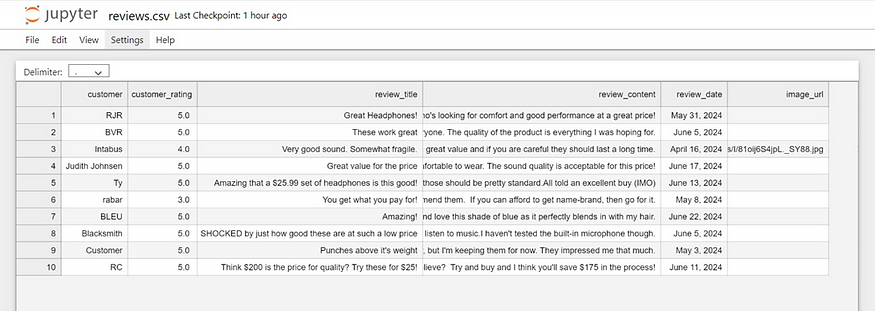
아마존 제품 리뷰를 스크랩하는 이유는 무엇입니까?
Amazon 제품 리뷰를 긁어 내면 비즈니스에 귀중한 통찰력을 제공 할 수 있습니다. 그들이하는 이유는 다음과 같습니다.
피드백 수집
모든 비즈니스에는 고객 요구 사항을 이해하고 제품 품질을 향상시키기 위해 변경 사항을 구현하기 위해 피드백이 필요합니다. 검토를 긁어 내면 비즈니스는 대량의 고객 피드백을 빠르고 효율적으로 수집 할 수 있습니다.
감정 분석
검토에 표현 된 감정을 분석하면 제품의 긍정적이고 부정적인 측면을 식별하는 데 도움이되어 비즈니스 결정에 정보가 제공됩니다.
경쟁사 분석
스크래핑을 통해 비즈니스는 경쟁 업체의 가격 및 제품 기능을 모니터링하여 시장에서 경쟁력을 유지할 수 있습니다.
비즈니스 확장 기회
고객의 요구와 선호도를 이해함으로써 비즈니스는 제품 라인을 확장하거나 새로운 시장에 진입 할 수있는 기회를 식별 할 수 있습니다.
콘텐츠를 수동으로 복사하고 붙여 넣는 것은 시간이 많이 걸리고 오류가 발생하기 쉽습니다. 웹 스크래핑이 시작되는 곳입니다. Python을 사용하여 Amazon 리뷰를 긁으면 프로세스를 자동화하고 수동 오류를 줄이며 정확한 데이터를 제공 할 수 있습니다.
아마존 리뷰를 스크래프하는 이점
- 능률: 데이터 추출을 자동화하여 시간과 리소스를 절약합니다.
- 정확성: 자동 스크립트로 인간 오류를 줄입니다.
- 큰 데이터 볼륨: 포괄적 인 분석을 위해 광범위한 데이터를 수집하십시오.
- 정보에 입각 한 의사 결정: 고객 피드백을 사용하여 데이터 중심 비즈니스 결정을 내립니다.
결론
이제 Python을 사용하여 Amazon Review를 긁어내는 방법을 다루었으므로 요소를 검사하여 다른 웹 사이트에 동일한 기술을 적용 할 수 있습니다. 기억해야 할 몇 가지 핵심 사항은 다음과 같습니다.
HTML 이해
HTML 구조에 익숙해 지십시오. 요소가 어떻게 중첩되고 문서 개체 모델 (DOM)을 탐색하는 방법을 아는 것은 스크랩하려는 데이터를 찾는 데 중요합니다.
CSS 선택기
CSS 선택기를 사용하여 웹 페이지에서 특정 요소를 정확하게 타겟팅하고 추출하는 방법을 알아보십시오.
파이썬 기본
Python 프로그래밍, 특히 HTTP 요청 요청 및 HTML 컨텐츠를 구문 분석하기위한 BeautifulSoup과 같은 라이브러리를 사용하는 방법을 이해하십시오.
요소 검사
브라우저 개발자 도구를 사용하여 연습 (웹 페이지를 마우스 오른쪽 버튼으로 클릭하고“검사”를 선택하거나 CTRL+Shift+i를 누르면 HTML 구조를 검사하십시오. 이를 통해 스크랩하려는 데이터를 보유하는 태그와 속성을 찾는 데 도움이됩니다.
오류 처리
네트워크 오류 또는 웹 페이지 구조의 변경과 같은 가능한 문제를 처리하기 위해 코드에 오류 처리를 추가하십시오.
법적, 윤리적 고려 사항
웹 스크래핑의 법적 및 윤리적 규칙을 준수하기 위해 항상 웹 사이트의 robots.txt 파일 및 서비스 약관을 확인하십시오. 이러한 영역을 마스터하면 다양한 웹 사이트에서 데이터를 자신있게 긁어서 귀중한 통찰력을 수집하고 자세한 분석을 수행 할 수 있습니다.










: 아우라 카버부터 아우라 잉크까지")


Post Comment