내부 살펴보기: 질문 도우미를 구축한 방법(및 이유)
")
[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2026.]
작년에 우리는 출시했습니다.[–>Staging Ground 새로운 질문자가 Stack Overflow에 질문이 공개적으로 게시되기 전에 전용 공간에서 숙련된 사용자로부터 초안에 대한 피드백을 얻을 수 있도록 지원합니다. 그 이후로 게시된 질문의 질이 눈에 띄게 향상되었습니다. 그러나 질문이 사람의 피드백을 받고 전체 Staging Ground 프로세스를 통과하는 데는 여전히 시간이 걸립니다.
리뷰어들은 또한 동일한 댓글을 계속해서 반복하고 있다는 사실을 알아차렸습니다. 이 게시물은 여기에 속하지 않으며, 컨텍스트가 누락되었으며, 중복된 게시물입니다. 전통적인 스택 오버플로 방식에는 올바른 상황에 적용할 수 있는 댓글 템플릿도 있습니다. 이는 기계 학습과 AI를 사용하여 일반적인 사례를 식별하고 프로세스 속도를 높여 인간 검토자가 보다 미묘한 사례를 다루는 데 시간을 할애할 수 있는 기회처럼 보였습니다. 와의 파트너십 덕분에[–>Google 자동화된 피드백을 테스트, 식별 및 생성하는 데 도움이 되는 견고한 AI 도구(Gemini)가 있었습니다.
결국 우리는 질문 품질을 평가하고 적절한 피드백을 결정하려면 생성 AI 솔루션 외에도 몇 가지 고전적인 ML 기술이 필요하다는 사실을 발견했습니다. 이 글에서는 우리가 어떻게 결과를 고려하고, 구현하고, 측정했는지 살펴보겠습니다.[–>Question Assistant.
LLM은 텍스트에 대한 많은 유용한 통찰력을 제공할 수 있으므로 특정 카테고리의 질문에 대한 품질 등급을 생성할 수 있는지 자연스럽게 궁금했습니다. 시작하기 위해 우리는 컨텍스트 및 배경, 예상 결과, 형식 및 가독성이라는 세 가지 범주를 사용하여 프롬프트에 정의했습니다. 이러한 카테고리는 새로운 질문자가 Staging Ground에서 질문을 개선할 수 있도록 리뷰어가 동일한 댓글을 반복적으로 작성하는 가장 일반적인 영역이기 때문에 선택되었습니다.
LLM을 사용한 테스트에서는 품질 평가를 안정적으로 예측하고 서로 상관된 피드백을 제공할 수 없는 것으로 나타났습니다. 피드백 자체는 반복적이었고 카테고리와 일치하지 않았습니다. 예를 들어 세 가지 카테고리 모두 정기적으로 라이브러리 버전이나 프로그래밍 언어에 대한 피드백을 포함했지만 이는 그다지 유용하지 않았습니다. 더 나쁜 것은 질문 초안이 업데이트된 후에도 품질 평가 및 피드백이 변경되지 않는다는 것입니다.
개념 자체가 본질적으로 주관적일 때 LLM이 질문의 품질을 안정적으로 평가하려면 데이터를 통해 품질 질문이 무엇인지 정의해야 했습니다. 스택 오버플로에 대한 지침이 있지만[–>how to ask a good question 품질은 수치로 쉽게 환산할 수 있는 것이 아닙니다. 즉, ML 모델을 훈련하고 평가하는 데 사용할 수 있는 레이블이 지정된 데이터 세트를 만들어야 했습니다.
우리는 질문을 평가하는 방법에 대한 데이터가 포함된 정답 데이터 세트를 만드는 것부터 시작했습니다. 1,000명의 질문 검토자에게 보낸 설문 조사에서 우리는 그들에게 세 가지 범주에서 1~5점 척도로 질문의 품질을 평가하도록 요청했습니다. 152명의 참가자가 설문조사를 완전히 완료했습니다. 결과를 실행한 후[–>Krippendorff’s alpha 매우 낮은 점수를 얻었습니다. 이는 이 레이블이 지정된 데이터가 신뢰할 수 있는 교육 및 평가 데이터가 되지 않음을 의미합니다.
데이터를 계속 탐색하면서 숫자 등급은 실행 가능한 피드백을 제공하지 않는다는 결론에 도달했습니다. 누군가 카테고리에서 3점을 받았다면 질문을 게시하기 위해 카테고리를 개선해야 한다는 뜻인가요? 숫자 평점은 질문의 개선이 필요한 내용, 방법, 위치에 대한 맥락을 제공하지 않습니다.
품질을 결정하기 위해 LLM을 사용할 수는 없지만 설문조사를 통해 해당 목적을 위한 피드백 범주의 중요성이 확인되었습니다. 이로 인해 우리는 이전에 언급한 각 범주에 대한 피드백 지표를 구축하는 대안적인 접근 방식을 취하게 되었습니다. 점수를 직접 예측하는 대신 질문이 해당 특정 지표에 대한 피드백을 받아야 하는지 여부를 나타내는 개별 모델을 구축했습니다.
광범위한 응답과 일반적인 출력이 가능한 LLM만 사용하는 대신 개별 로지스틱 회귀 모델을 만들었습니다. 이는 질문 제목과 본문을 기반으로 이진 응답을 생성합니다. 본질적으로: 이 질문에 특정 댓글 템플릿을 적용해야 합니까, 아니면 필요하지 않습니까?
첫 번째 실험에서는 컨텍스트와 배경에 대한 모델을 구축하기 위해 단일 카테고리를 선택했습니다. 우리는 카테고리를 4개의 개별적이고 실행 가능한 피드백 지표로 분류했습니다.
- 문제 정의: 문제나 목표에 사용자가 달성하려는 작업을 이해하기 위한 정보가 부족합니다.
- 시도 세부정보: 질문에는 시도한 내용과 관련 코드(관련된 경우)에 대한 추가 정보가 필요합니다.
- 오류 세부정보: 질문에는 오류 메시지 및 디버깅 로그(관련된 경우)에 대한 추가 정보가 필요합니다.
- MRE 누락: 문제를 재현하는 코드 부분을 사용하여 재현 가능한 최소 예제가 누락되었습니다.
우리는 Staging Ground 게시물에 대한 리뷰어 댓글을 클러스터링하여 피드백 지표를 도출하여 이들 사이의 공통 주제를 찾았습니다. 편리하게도 이러한 테마는 기존 댓글 템플릿과 일치하고 종료 이유에 대한 질문을 하므로 모델을 훈련하는 데 과거 데이터를 사용하여 이를 감지할 수 있었습니다. 해당 리뷰어 의견과 종료 의견은 모두 다음을 사용하여 벡터화되었습니다.[–>term frequency inverse document frequency (TF IDF) 해당 기능을 로지스틱 회귀 모델에 전달하기 전입니다.
품질 지표를 기반으로 질문에 플래그를 지정하기 위해 보다 전통적인 ML 모델을 구축하고 있었지만 실행 가능한 피드백을 제공하려면 여전히 이를 워크플로의 LLM과 결합해야 했습니다. 표시기가 질문에 플래그를 지정하면 일부 시스템 프롬프트와 함께 질문과 함께 미리 로드된 응답 텍스트를 Gemini로 보냅니다. 그런 다음 Gemini는 이를 종합하여 지표를 다루지만 질문에 특정한 피드백을 생성합니다.
이 인어 다이어그램은 흐름을 보여줍니다.
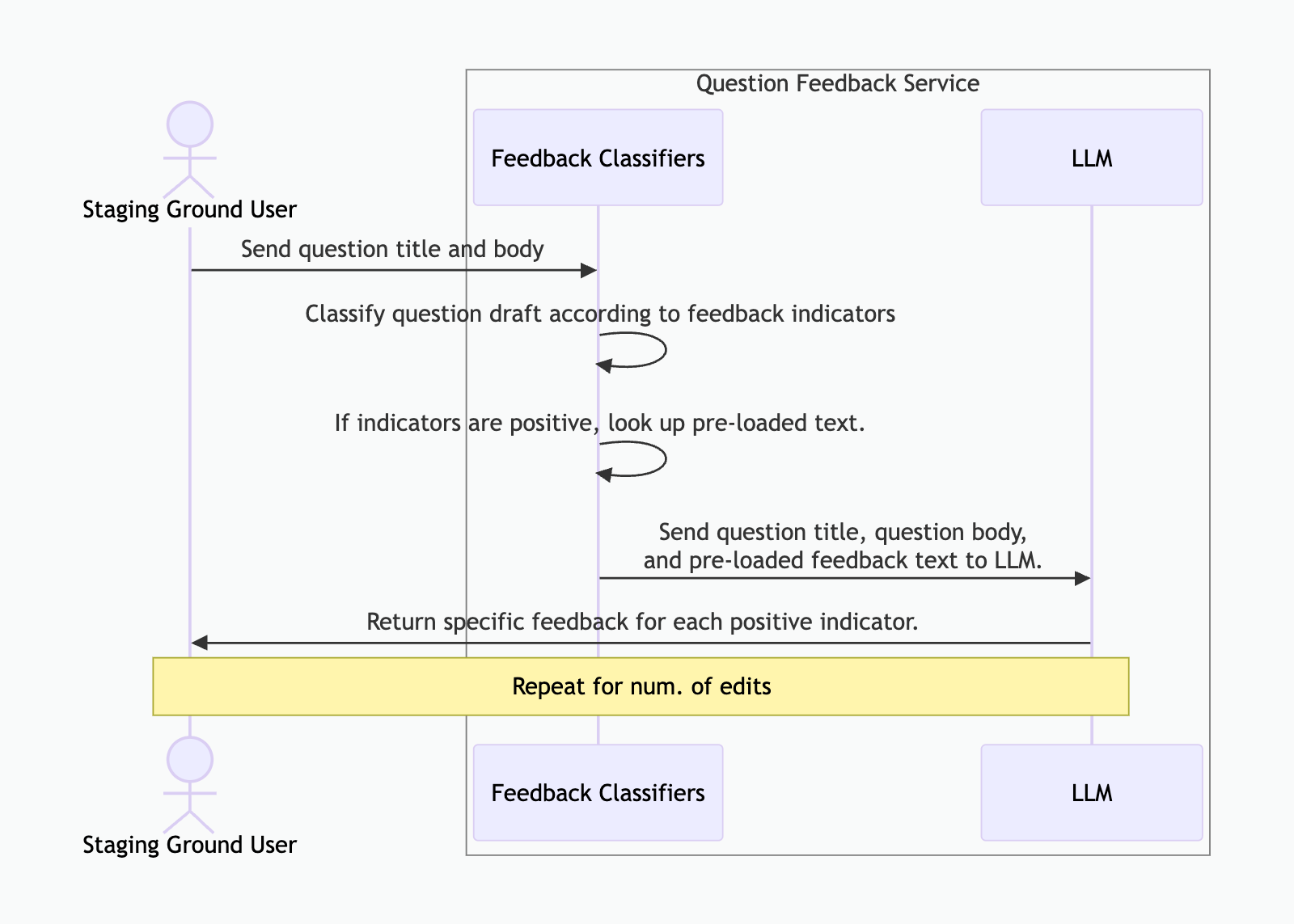
우리는 Azure Databricks 생태계 내에서 이러한 모델을 교육하고 저장했습니다. 프로덕션에서는 Azure Kubernetes의 전용 서비스가 Databricks Unity Catalog에서 다운로드하고 모델을 호스팅하여 피드백 요청 시 예측을 생성합니다.
그러면 모델이 피드백 생성을 시작할 준비가 되었습니다.
우리는 이 실험을 두 단계로 진행했습니다. 첫 번째는 Staging Ground에서만, 그 다음은 Staging Ground에서 수행했습니다.[–>stackoverflow.com 모든 질문자에게[–>Ask Wizard. 성공을 측정하기 위해 Azure Event Hub를 통해 이벤트를 수집하고 예측 및 결과를 Datadog에 기록하여 생성된 피드백이 사용자에게 도움이 되었는지 여부를 이해하고 지표 모델의 향후 반복을 개선했습니다.
첫 번째 실험은 Staging Ground에서 이루어졌으며, 여기서는 첫 번째 질문 초안을 작성하는 데 가장 큰 도움이 필요할 수 있는 새로운 질문자에게 집중할 수 있었습니다. 우리는 이를 A/B 테스트로 실행했습니다. 여기서 모든 적격한 Staging Ground 질문자는 실험에 할당되었으며 제어 그룹과 변형 그룹 간에 50/50을 나눴습니다. 통제 그룹은 Gemini의 도움을 받지 못한 반면, 변형 그룹은 Gemini의 도움을 받았습니다. 우리의 목표는 질문 도우미가 기본 사이트에 승인된 질문 수를 늘릴 수 있는지 확인하는 것이었습니다. 그리고 질문을 검토하는 데 소요되는 시간을 줄입니다.
실험 결과는 원래 목표 측정항목을 기준으로 결론이 나지 않았습니다. 대조군에 비해 변형 그룹에서는 승인률이나 평균 검토 시간이 크게 향상되지 않았습니다. 하지만 이 솔루션은 실제로 다른 문제를 해결하는 것으로 나타났습니다. 질문 성공률이 의미 있게 증가한 것을 확인했습니다. 즉, 사이트에 계속 열려 있고 답변을 받거나 게시 점수가 최소 2점 이상인 질문입니다. 따라서 우리가 원래 찾고 있던 것을 찾지 못했지만, 실험을 통해 질문 도우미가 질문자에게 가치가 있고 질문 품질에 긍정적인 영향을 미친다는 것이 여전히 검증되었습니다.
두 번째 실험에서는 모든 적격 질문자를 대상으로 A/B 테스트를 실행했습니다.[–>Ask Question 질문 마법사가 있는 페이지입니다. 이번에는 첫 번째 실험의 결과를 확인하고 질문 도우미가 더 숙련된 질문자에게도 도움이 될 수 있는지 확인하고 싶었습니다.
두 실험 모두에서 +12%의 꾸준한 성공률을 확인했습니다. 의미 있는 성공률과 조사 결과의 일관성을 바탕으로 2025년 3월 6일에 Stack Overflow의 모든 질문자가 질문 도우미를 사용할 수 있게 되었습니다.
연구 및 초기 개발에서는 방향을 바꾸는 것이 드문 일이 아닙니다. 그러나 영향력을 제공하지 않는 경로에 있을 때를 깨닫고 새로운 논리로 전환하는 것은 모든 퍼즐 조각이 다른 방식으로 여전히 서로 맞는지 확인하는 데 중요합니다. 전통적인 ML과 Gemini의 협력을 통해 우리는 질문자가 질문을 개선하는 데 활용할 수 있는 보다 구체적이고 상황에 맞는 피드백을 제공하기 위해 제안된 지표 피드백과 질문 텍스트를 융합하여 사용자가 필요한 지식을 더 쉽게 찾을 수 있었습니다. 이는 모든 사람이 더 쉽게 질문하고, 답변하고, 지식에 기여할 수 있도록 핵심 Q&A 흐름을 개선하려는 우리 작업의 한 단계입니다. 아직 질문 도우미가 끝나지 않았습니다. 커뮤니티 제품 팀은 지표 모델을 반복하고 이 기능을 통해 질문 경험을 더욱 최적화할 수 있는 방법을 찾고 있습니다.









, 테스트 및 검토됨")



Post Comment