LLM의 접두사 캐싱으로 90% 비용 절감

LLM 추론 비용을 최대 90%까지 슬래시 할 수있는 기술이 있다는 것을 알고 있습니까? Prefix Caching은 필요한 비용을 많이 절약 할 수있는 아이디어입니다. 인류와 같은 자이언트뿐만 아니라 오픈 소스 LLM을 사용하는 사람도 사용할 수있는 게임 변경 최적화 기술입니다.

이 기술의 커튼을 뒤로 당겨 봅시다!
Chatgpt가 응답하기에 너무 오래 기다린 적이 있습니까? 당신은 혼자가 아닙니다.
충격적인 진실은 다음과 같습니다. LLM 응용 프로그램의 모든 프롬프트 중 최대 70%의 프롬프트가 반복적이거나 유사합니다. 누군가가 “날씨가 뭐야?”라고 물을 때마다. 또는 “이것을 프랑스어로 번역하십시오”또는 “엄마를위한 선물 아이디어”, 우리는 거의 동일한 프롬프트를 컴퓨팅 전원 처리를 태우고 있습니다. 그러나 분산 시스템에서 이러한 중복 계산은 곱셈입니다. 분산 클러스터의 각 노드는 시간당 수천 번 동일한 프롬프트 패턴을 처리 할 수 있습니다. 당신은 돈을 피우고 있습니다.
얼마 전, 의인성은 그들이 어떻게 활용하는지에 대해 자세히 설명했습니다 피오두막 추론 비용을 90%줄입니다. 이것이 부분적으로 일부 개발자가 Claude 에서이 기능을 테스트하기를 열망하는 이유였습니다. VLLM, TRT-LLM 및 SGLANG과 같은 수많은 오픈 소스 LLM 런타임, 기능 에이활기 넘치는 접두사 캐싱도 알려져 있습니다 기음온 텍스트 캐싱. 이 기능에서는 공통 접두사가있는 요청에 대한 입력 프롬프트가 자동으로 캐시됩니다.
접두사 캐싱은 어떻게 작동합니까?
접두사 캐싱을 더 잘 이해하려면 먼저 LLM 추론의 작동 방식에주의를 기울여야합니다.
높은 수준에서는 두 단계가 포함됩니다.
- 주어진 입력 토큰 시퀀스를 정방향 패스로 처리하십시오. 이것을 프리 필 단계.
- 에서 디코딩 단계출력 토큰은 First에서 Last까지 연속적으로 생성되며 현재 토큰은 마지막 토큰에 따라 달라집니다.
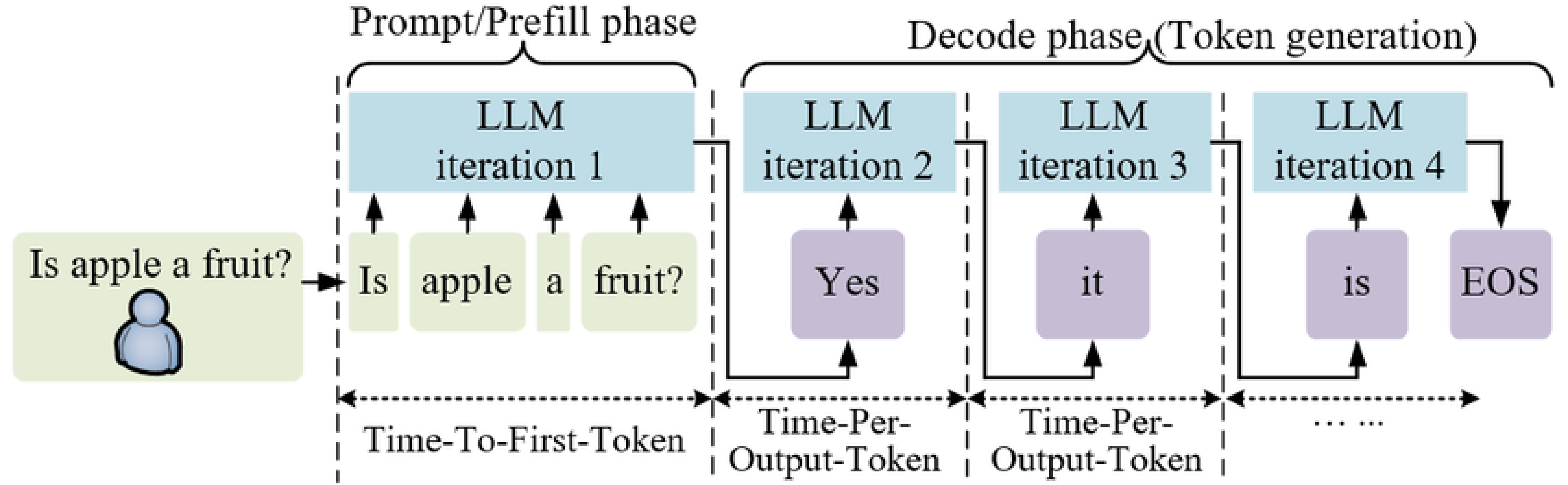
프로세스는 자동 회귀 (이전 토큰에 대한 새로운 토큰의 의존성)이므로 효과적인 메모리 관리가 중요합니다. 이것은 일반적인 관행으로 이어졌습니다 KV 캐싱 중간 상태. 간단한 프롬프트와 다릅니다 시맨틱 캐싱 데이터베이스에 전체 텍스트 입력 및 출력을 배치하지 않으므로 정확히 일치하는 (또는 동일한 쿼리) 만 캐시를 치고 즉시 응답을받는 이점을 얻습니다.
LLM이 처리 될 때 프리 필 단계 동안 토큰그것은 계산합니다 “주목,” 즉, 각 토큰이 다른 토큰과 어떤 관련이 있는지. 이 계산은 각 토큰에 대한 키 및 가치 행렬을 생성합니다. KV 캐싱이 없으면 모델이 이전 토큰을 되돌아 볼 때마다 다시 계산해야합니다. KV 캐싱은 한 세대에 대해서만 기능 할 수있는 의도로 개발되었으며, 이는 하나의 출력을 생성하는 과정에서만 중간 상태를 포착 할 것임을 의미합니다.
접두사가 동일한 두 가지 요청이 있으면 어떻게해야합니까?
KV 캐싱에 대한이 아이디어는 변형되었습니다 접두사 캐싱,,, 그러한 상태가 저장되고 동일한 접두사를 포함하는 프롬프트에 대해 다른 응답을 생성 할 때 사용될 수 있습니다. 간단한 비유의 경우 계산 방법을 고려하십시오 2 * 6 * 3 * 5 일단 당신이 이미 계산 한 후에 2 * 6. 당신은 단순히 계산을 재사용 할 것입니다 2 * 6 순서대로 필요할 때마다 다시 계산하는 대신.
이것이 내 응용 프로그램에 어떻게 도움이됩니까?
다음 모범 사례를 사용하여 접두사 캐싱 기능을 최대한 활용할 수 있습니다.
전략적 프롬프트 구조
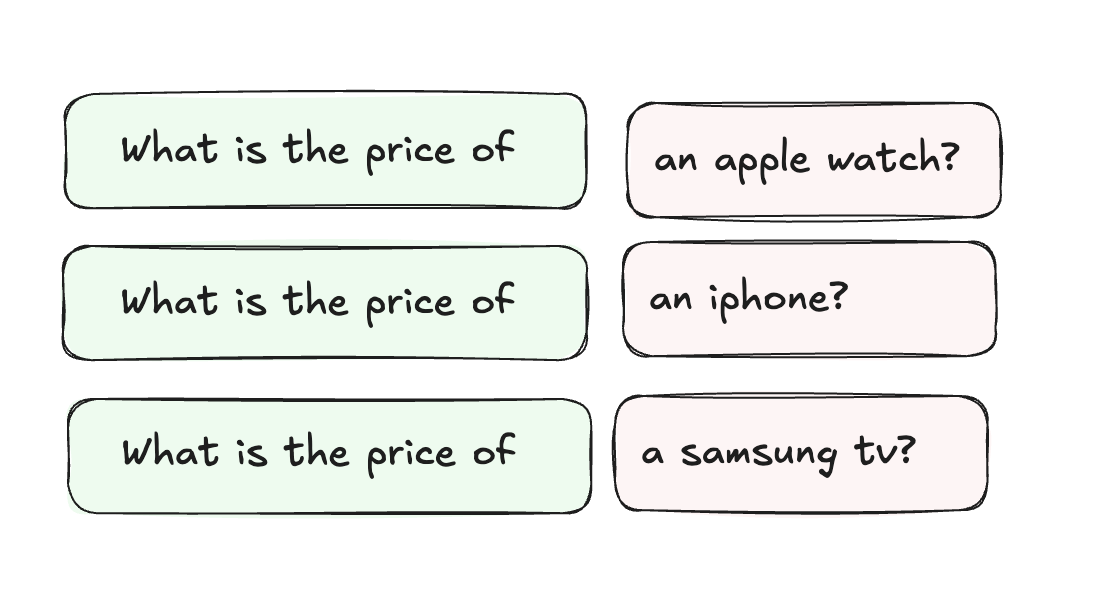
프롬프트 시작시 시스템 프롬프트, 기본 지침 또는 공유 컨텍스트와 같은 상수 요소를 배치하십시오. (그림 2). 이것은 여러 쿼리에 대해 재사용 할 수있는 기초를 만듭니다. 동적 또는 특정 컨텐츠는 끝까지 배치 할 수 있습니다.
요청 요청
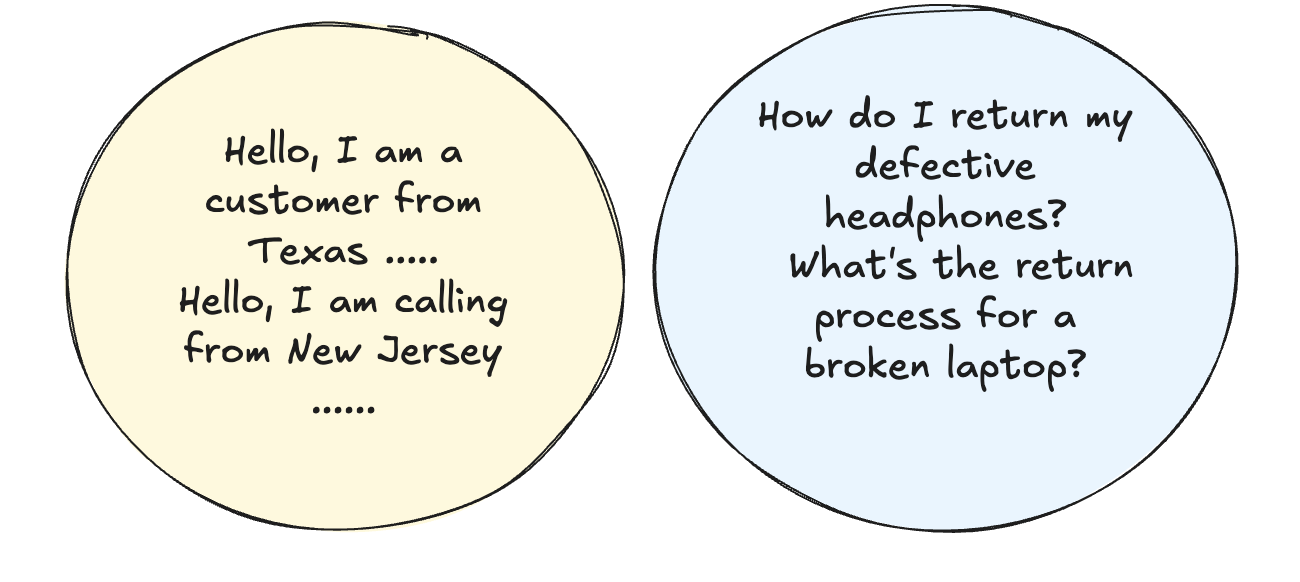
함께 요청합니다 (그림 3) 공통 구조/접두사를 공유합니다. 예를 들어, 일반적인 인사말 또는 경례로 시작하는 여러 고객 쿼리를 처리하는 경우 계산을 캐시 및 재사용 할 수 있으므로 정리하는 것이 좋습니다.
캐시 사용을 모니터링합니다
캐시 활용 메트릭의 강력한 모니터링을 구현하십시오.
히트 앤 미스 요율을 추적합니다.
- 다른 접두사보다 어떤 접두사가 더 두드러진 지 알아 내기 위해
- 캐시 미스에서 패턴을 식별합니다
이러한 통찰력을 사용하여 최적의 성능을 위해 프롬프트 구조를 개선하십시오.
빠른 예
아래의 예는 여러 쿼리가 동일한 컨텍스트를 공유 할 때 Prefix 캐싱이 LLM 추론을 최적화 할 수있는 방법을 보여줍니다. 간단한 직원 데이터베이스 테이블을 사용하고 내용에 대해 다른 쿼리를 만들 것입니다.
import time
from vllm import LLM, SamplingParams
# A small table containing employee information
LONG_PROMPT = """You are a helpful assistant that recognizes content in markdown tables. Here is the table:
| ID | Name | Department | Salary | Location | Email |
|----|---------------|------------|---------|-------------|---------------------|
| 1 | Alice Smith | Engineering| 85000 | New York | [email protected] |
| 2 | Bob Johnson | Marketing | 65000 | Chicago | [email protected] |
| 3 | Carol White | Sales | 75000 | Boston | [email protected] |
| 4 | David Brown | Engineering| 90000 | Seattle | [email protected] |
| 5 | Eve Wilson | Marketing | 70000 | Austin | [email protected] |
"""
def get_generation_time(llm, sampling_params, prompts):
start_time = time.time()
output = llm.generate(prompts, sampling_params=sampling_params)
end_time = time.time()
print(f"Output: {output[0].outputs[0].text}")
print(f"Generation time: {end_time - start_time:.2f} seconds")
# Initialize LLM with prefix caching enabled
llm = LLM(
model="lmsys/longchat-13b-16k",
enable_prefix_caching=True
)
sampling_params = SamplingParams(temperature=0, max_tokens=50)
# First query - will compute and cache the table
get_generation_time(
llm,
sampling_params,
LONG_PROMPT + "Question: What is Alice Smith's salary? Your answer: Alice Smith's salary is "
)
# Second query - will reuse the cached table computation
get_generation_time(
llm,
sampling_params,
LONG_PROMPT + "Question: What is Eve Wilson's salary? Your answer: Eve Wilson's salary is "
)이 코드를 실행하여 쿼리 간의 실제 시차를 확인하십시오. 두 번째 쿼리는 캐시 된 테이블 컨텍스트를 재사용 할 때 현저히 빠르야합니다. 실제 타이밍은 하드웨어 및 설정에 따라 다릅니다.
결론
LLM 애플리케이션을위한 강력한 최적화 기술로서의 접두사 캐싱 표면. 위에서 설명한 모범 사례를 구현하면 개발자가 응답 품질을 방해하지 않고 추론 비용을 크게 줄일 수 있습니다. 실용적인 예는 오늘날 자신의 응용 프로그램 에서이 기술을 활용하기가 얼마나 쉬운 지 보여줍니다.











Post Comment