실습 자바 및 랑크 인 4J 가이드

부인 성명: 이 기사는 학습 및 데모 목적을 위해 구축 된 실험 프로젝트를 자세히 설명합니다. 설명 된 구현은 생산 급 솔루션으로 의도되지 않습니다. 코드의 일부는 JetBrains의 AI 에이전트 인 Junie를 사용하여 생성되었습니다.
GPT-4, LLAMA 및 Gemini와 같은 대형 언어 모델 (LLM)은 우리가 정보와 상호 작용하는 방식에 혁명을 일으켰습니다. 그러나 그들의 지식은 일반적으로 그들이 훈련 된 데이터로 제한됩니다. 이해하는 AI 보조원이 필요하다면 어떨까요? 당신의 특정 도메인 지식 – 회사의 내부 문서, 제품 사양 또는 복잡한 시스템의 운영 데이터?
RAG (Resprieve-Aug-Augmented Generation)가 들어 오는 곳입니다. Rag는 특정 지식 소스에서 검색된 관련 정보를 제공하여 LLM을 향상시킵니다. ~ 전에 그들은 응답을 생성합니다. 이를 통해 원래 교육을받지 않은 데이터를 기반으로 질문에 답변 할 수 있습니다.
이 기사는 그러한 시스템을 구축하려는 Java 개발자를위한 실습 가이드입니다. 우리는 Java와 Langchain4J 라이브러리를 사용하여 사용자 정의 지식 기반으로 “채팅”할 수있는 간단한 응용 프로그램을 작성합니다. Langchain4J는 Java 생태계 내에서 LLM을 통합하고 AI 응용 프로그램을 구축하는 프로세스를 단순화합니다.
이 가이드가 끝날 무렵, 당신은 다음과 같은 기본 헝겊 파이프 라인을 만들 것입니다.
- 지식 기반을 나타내는 로컬 텍스트 파일의 정보를로드합니다.
- LLM이 액세스 할 수있는 방식 으로이 정보를 프로세스하고 저장합니다.
- LLM (예 : OpenAi의 GPT 또는 Ollama를 통한 로컬 모델)을 사용하여 검색된 지식과 결합하여 질문에 답변합니다.
검색 섭취 세대 (RAG) 란 무엇입니까?
LLM에 내부 시스템의 특정 오류 코드에 대한 질문을한다고 상상해보십시오. 헝겊이 없으면 LLM은 모른다는 것을 추측하거나 말할 수 있습니다.
Rag는 중요한 단계를 추가하여 이것을 변경합니다.
- 검색하다: 질문을 할 때 시스템은 먼저 쿼리와 관련된 정보를 위해 특정 지식 기반 (문서, 데이터베이스 등)을 검색합니다.
- 보강:이 검색된 정보 ( “컨텍스트”)는 원래 질문에 추가되어 LLM에 더 자세한 프롬프트로 전송됩니다.
- 생성하다: LLM은 귀하의 질문과 제공된 컨텍스트를 모두 사용하여 정보에 입각 한 답변을 생성합니다.
기본적으로 Rag는 LLM에 도메인 별 질문에 답하기 직전에 관련 “치트 시트”를 제공합니다.
왜 langchain4j?
Langchain4J는 인기있는 Python Langchain 프로젝트에서 영감을 얻은 Java 라이브러리입니다. Java에서 LLM 기반 응용 프로그램의 개발을 간소화하기위한 유용한 추상화 및 도구를 제공합니다. 다음과 같은 작업을 단순화합니다.
- 다양한 LLM 제공 업체 (Openai, Ollama, Gemini 등)와 연결.
- 프롬프트 및 채팅 메모리 관리.
- 문서로드 및 변환.
- 임베딩 모델 및 벡터 매장과 통합 (래그에 필수적).
- AI 서비스 및 에이전트 생성.
Langchain4J를 사용한다는 것은 API 통합 및 AI 작업에 대한 데이터 처리에 종종 관련된 상용구 코드보다는 응용 프로그램의 논리에 더 집중할 수 있음을 의미합니다.
시나리오 : 운영 지식 쿼리
이 데모를 위해 본격적인 산업 시스템 인터페이스를 구축하지는 않습니다. 대신, 기술 구성 요소, 해당 상태 및 알려진 문제 또는 운영 규칙에 대한 기본 정보가 포함 된 지식 기반을 시뮬레이션합니다. 이 정보는 간단한 텍스트 파일에 저장됩니다. 우리의 목표는 질문에 따라 질문에 답할 수있는 채팅 인터페이스를 구축하는 것입니다. 오직 이 파일의 정보에서 Rag를 사용합니다.
전제 조건
코딩을 시작하기 전에 다음과 같은 설치가 있는지 확인하십시오.
- 자바 개발 키트 (JDK): 버전 17 이상이 권장됩니다. JDK 21 이상이 선호됩니다.
- 도구 빌드 도구: Apache Maven 또는 Gradle. 여기에서 Maven 예제를 사용하겠습니다.
- IDE: java 확장 기능을 갖춘 Intellij Idea, Eclipse 또는 VS 코드와 같은 Java IDE.
- LLM 액세스: 큰 언어 모델 (LLM)과 상호 작용하는 방법이 필요합니다. 하나 선택 :
- 옵션 A (OpenAi): OpenAI의 API 키. 웹 사이트에서 하나를 얻을 수 있습니다. Langchain4J는 “데모”를 기본, 속도 제한 테스트의 키로 사용할 수 있습니다.
- 옵션 B (Ollama – 지역): 기계에 Ollama를 설치하십시오. 설치 후 명령 줄 (예 : Ollama Pull Llama3 또는 Ollama Pull Mistral)을 통해 모델을 당기십시오. 이를 통해 LLM을 완전히 로컬로 실행할 수 있습니다.
1 단계 : 프로젝트 설정 (Maven)
IDE에서 새로운 Maven 프로젝트를 만듭니다. pom.xml 파일을 열고 필요한 langchain4j 종속성을 추가하십시오.
dev.langchain4j
langchain4j
${langchain4j.version}
dev.langchain4j
langchain4j-open-ai
${langchain4j.version}
dev.langchain4j
langchain4j-ollama
${langchain4j.version}
당신은 둘 중 하나를 선택할 수 있습니다 langchain4j-open-ai 또는 langchain4j-ollama 의존.
2 단계 : 지식 기반 파일 만들기
Rag 시스템을 공급하려면 몇 가지 원시 데이터가 필요합니다. 프로젝트 구조에서 SRC/Main/Resources라는 디렉토리를 만듭니다. 이 디렉토리 내에서 두 개의 텍스트 파일을 만듭니다.
src/main/resources/components.txt
Component ID: PUMP-001. Type: Centrifugal Pump. Status: Running. Connected to: VALVE-001, PIPE-002. Location: Sector A.
Component ID: VALVE-001. Type: Gate Valve. Status: Open. Connected to: PUMP-001, TANK-A. Location: Sector A.
Component ID: SENSOR-T1. Type: Temperature Sensor. Monitors: PUMP-001 Casing. Reading: 65C. Unit: Celsius. Location: Sector A.
Component ID: SENSOR-P1. Type: Pressure Sensor. Monitors: PIPE-002. Reading: 150. Unit: PSI. Location: Sector B.
Component ID: MOTOR-001. Type: Electric Motor. Status: Running. Drives: PUMP-001. Location: Sector A.src/main/resources/knowledge.txt
Fault ID: F001. Description: High Temperature on PUMP-001. Possible Causes: Low lubrication, bearing wear, blocked outlet VALVE-001. Recommended Action: Check lubrication levels and bearing condition.
Event ID: E001. Description: Pressure drop in PIPE-002 below 100 PSI. Related Components: PUMP-001, VALVE-001, SENSOR-P1. Possible Causes: Leak in PIPE-002, PUMP-001 failure, VALVE-001 partially closed.
Rule ID: R001. Condition: If SENSOR-T1 reading > 80C. Action: Generate HIGH_TEMP_ALERT for PUMP-001. Priority: High.
Maintenance Note M001: PUMP-001 bearings last replaced 6 months ago. Next inspection due in 1 month.
Safety Procedure S001: Before servicing PUMP-001, ensure MOTOR-001 is locked out and VALVE-001 is closed.이 파일에는 시뮬레이션 된 시스템에 대한 간단하고 사실적인 진술이 포함되어 있습니다.
3 단계 : 지식 수집 (래그 파이프 라인 구축)
이제 우리는 Java 코드를 작성하여 이러한 파일을로드하고 처리하고 검색 할 수있는 방식으로 저장합니다. 이 과정은 다음과 같습니다.
- 로딩: 텍스트 파일에서 내용을 읽습니다.
- 파편: 문서를 더 작고 관리하기 쉬운 덩어리 (또는 “세그먼트”)로 나눕니다. LLM은 한 번에 처리 할 수있는 텍스트의 양에 제한이 있고 작은 덩어리는 종종 더 관련성이 높은 검색으로 이어지기 때문에 중요합니다.
- 임베딩: 임베딩 모델을 사용하여 각 텍스트 세그먼트를 숫자 벡터 ( “포함”)로 변환합니다. 이 벡터는 텍스트의 의미 론적 의미를 포착합니다. 비슷한 개념에는 비슷한 벡터가 있습니다.
- 저장: “임베딩 스토어”(종종 벡터 데이터베이스이지만이 데모에는 간단한 메모리 저장소를 사용 하겠지만)에 해당 텍스트 세그먼트와 함께 이러한 임베드를 저장합니다.
새 Java 클래스 만들기, KnowledgeBaseIngestor.java:
package com.example; // Use your package name
package ca.bazlur.util;
import ca.bazlur.service.KnowledgeBaseService;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel; // Choose one
// import dev.langchain4j.model.ollama.OllamaEmbeddingModel; // Choose one
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.io.IOException;
import java.io.InputStream;
import java.net.URISyntaxException;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.Objects;
public class KnowledgeBaseIngestor {
/**
* Loads documents from resource files, creates embeddings, and stores them in an in-memory store.
*
* @return An EmbeddingStore containing the processed knowledge base.
* @throws URISyntaxException if the resource file paths are invalid.
*/
public static EmbeddingStore ingestData() throws URISyntaxException, IOException {
System.out.println("Starting knowledge base ingestion...");
// --- 1. Load Documents ---
Document componentsDoc = loadDocumentFromResource("components.txt", new TextDocumentParser());
Document knowledgeDoc = loadDocumentFromResource("knowledge.txt", new TextDocumentParser());
List documents = List.of(componentsDoc, knowledgeDoc);
System.out.println("Documents loaded successfully.");
// --- 2. Setup Embedding Model ---
// Choose *one* embedding model provider:
// Option A: OpenAI (Requires OPENAI_API_KEY environment variable or use "demo")
// System.out.println("Initializing OpenAI Embedding Model...");
// EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
// .apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
// .logRequests(true) // Optional: Log requests to OpenAI
// .logResponses(true) // Optional: Log responses from OpenAI
// .build();
// Option B: Ollama (Requires Ollama server running locally)
System.out.println("Initializing Ollama Embedding Model...");
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl(" // Default Ollama URL
.modelName("llama3")
.build();
System.out.println("Embedding Model initialized.");
// --- 3. Setup Embedding Store ---
// We use a simple in-memory store for this demo.
// For persistent storage, explore options like Chroma, Pinecone, Weaviate, etc.
System.out.println("Initializing In-Memory Embedding Store...");
EmbeddingStore embeddingStore = new InMemoryEmbeddingStore();
System.out.println("Embedding Store initialized.");
// --- 4. Setup Ingestion Pipeline ---
// Define how documents are split into segments (chunking strategy)
// recursive(maxSegmentSize, maxOverlap) splits text recursively, trying to keep paragraphs/sentences together.
// 300 characters per segment, 30 characters overlap between segments.
DocumentSplitter splitter = DocumentSplitters.recursive(300, 30);
System.out.println("Using recursive document splitter (300 chars, 30 overlap).");
// EmbeddingStoreIngestor handles splitting, embedding, and storing.
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
// --- 5. Ingest Documents ---
System.out.println("Ingesting documents into the embedding store...");
ingestor.ingest(documents);
System.out.println("Ingestion complete. Embedding store contains");
return embeddingStore;
}
/**
* Helper method to get the Path of a resource file.
* Handles running from IDE and within a JAR file.
* @param resourceName The name of the file in src/main/resources
* @return The Path object for the resource.
* @throws URISyntaxException If the resource URL is malformed.
* @throws RuntimeException If the resource is not found.
*/
private static Document loadDocumentFromResource(String resourceName, DocumentParser parser) throws IOException {
try (InputStream inputStream = getResourceAsStream(resourceName)) {
Objects.requireNonNull(inputStream, "Resource not found: " + resourceName);
return parser.parse(inputStream);
}
}
protected static InputStream getResourceAsStream(String resourceName) {
return KnowledgeBaseService.class.getClassLoader().getResourceAsStream(resourceName);
}
public static void main(String[] args) {
try {
EmbeddingStore store = ingestData();
} catch (URISyntaxException e) {
System.err.println("Error finding resource files: " + e.getMessage());
e.printStackTrace();
} catch (Exception e) {
System.err.println("An error occurred during ingestion: " + e.getMessage());
e.printStackTrace();
}
}
} 주요 클래스의 설명
- TextDocumentParser: 일반 텍스트 파일의 간단한 파서.
- DocumentsPlitters.recursive (): 문서를 세그먼트로 나누고 문장/단락 경계를 존중하려는 전략. 숫자 (예 : 300, 30)는 최대 세그먼트 크기와 세그먼트 간의 중첩을 제어합니다.
- EmbeddingModel (OpenAiembeddingModel / OllamaembeddingModel): 텍스트를 임베딩으로 변환하기위한 인터페이스 및 구현. 참고 : Ollama의 경우 Nomic-embed-Text와 같은 전용 임베딩 모델을 사용하는 것이 일반적으로 임베딩을 위해 채팅 모델을 사용하는 것보다 낫습니다.
- inmemoryembeddingstore: 데이터를 메모리에 유지하는 EmbeddingStore의 기본 구현. 데모에 적합하지만 응용 프로그램이 직렬화되지 않으면 중지되면 데이터가 손실됩니다.
- 임베딩 스토어 스토어 스토어: 문서를 분할하고 세그먼트를 포함시키고 임베딩 스토어에 추가하는 과정을 조정합니다.
4 단계 : 채팅 인터페이스 구축 (aiservice)
이제 사용자 상호 작용을 처리 할 기본 응용 프로그램 클래스를 만듭니다. 그것은 :
- KnowledgeBaseingEStor를 호출하여 지식 기반을 초기화하십시오.
- 채팅 언어 모델 (응답을 생성하는 LLM)을 설정하십시오.
- 포함 된 스토어를 사용하여 사용자 쿼리와 관련된 컨텍스트를 찾는 ContentRestiever를 설정하십시오.
- Langchain4J의 aiservices를 사용하여 간단한 채팅 인터페이스를 만듭니다.
- 선택적으로 Chatmemory를 사용하여 조수가 대화 기록을 기억할 수 있습니다.
새 Java 클래스 만들기, KnowledgeAssistant.java:
package ca.bazlur.util;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.ollama.OllamaChatModel;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.store.embedding.EmbeddingStore;
import java.util.Scanner;
public class KnowledgeAssistant {
interface Assistant {
@SystemMessage("""
You are an AI assistant specialized in querying operational knowledge about technical systems
(components, status, faults, procedures). Answer user questions accurately and concisely,
relying *strictly* on the information provided in the context. Do not use any prior knowledge or make assumptions.
""")
String chat(String userMessage);
}
public static void main(String[] args) {
try {
// --- 1. Ingest Knowledge Base ---
EmbeddingStore embeddingStore = KnowledgeBaseIngestor.ingestData();
// --- 2. Setup Chat Model ---
// Option A: OpenAI
/*
System.out.println("Initializing OpenAI Chat Model...");
ChatLanguageModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
.modelName("gpt-4o") // Or gpt-4o, etc.
.logRequests(true)
.logResponses(true)
.build();
// We also need the corresponding embedding model for the retriever
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
.logRequests(true)
.logResponses(true)
.build();
*/
// Option B: Ollama
System.out.println("Initializing Ollama Chat Model...");
ChatLanguageModel chatModel = OllamaChatModel.builder()
.baseUrl("
.modelName("llama3") // Or mistral, etc.
.build();
// We also need the corresponding embedding model for the retriever
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("
.modelName("llama3")
.build();
System.out.println("Chat Model initialized.");
// --- 3. Setup Content Retriever (RAG) ---
System.out.println("Initializing Content Retriever...");
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel) // Use the *same* embedding model used during ingestion
.maxResults(3) // Retrieve top 3 most relevant segments
.minScore(0.6) // Filter out segments with relevance score below 0.6
.build();
System.out.println("Content Retriever initialized.");
// --- 4. Setup Chat Memory (Optional) ---
// This allows the assistant to remember previous parts of the conversation.
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
System.out.println("Chat Memory initialized (window size 10).");
// --- 5. Create the AiService ---
// AiServices wires together the chat model, retriever, memory, etc.
// It automatically implements the Assistant interface based on annotations and configuration.
System.out.println("Creating AI Service...");
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
System.out.println("AI Service created. Assistant is ready.");
// --- 6. Start Interactive Chat Loop ---
Scanner scanner = new Scanner(System.in);
System.out.println("\nAssistant: Hello! Ask me about the system components or known issues.");
while (true) {
System.out.print("You: ");
String userQuery = scanner.nextLine();
if ("exit".equalsIgnoreCase(userQuery)) {
System.out.println("Assistant: Goodbye!");
break;
}
String assistantResponse = assistant.chat(userQuery);
System.out.println("Assistant: " + assistantResponse);
}
scanner.close();
} catch (Exception e) {
System.err.println("An error occurred during assistant setup or chat: " + e.getMessage());
e.printStackTrace();
}
}
} 주요 클래스의 설명
- chatlanguagemodel (openaichatmodel / ollamachatmodel): 응답을 생성하는 핵심 LLM의 인터페이스 및 구현.
- embeddingstorecontentretriever: embeddingStore와 함께 작동하도록 특별히 설계된 ContentRestiever의 구현. 사용자 쿼리가 필요하고 사용을 포함합니다 같은 섭취하는 동안 사용되는 임베딩 모델은 유사한 임베딩을 포함하여 EmbeddingStore를 검색하고 해당 텍스트 세그먼트를 검색합니다.
- chatmemory (messagewindowchatmemory): 대화의 역사를 저장합니다. MessageWindowChatMemory는 마지막 N 메시지 만 유지합니다.
- Aveiring: Langchain4J의 강력한 공장으로 정의 된 인터페이스 (여기, 어시스턴트)를 구현합니다. 자동으로 처리합니다.
- 사용자 메시지를 가져옵니다.
- (ContentRestiever가 제공되는 경우) 관련 컨텍스트를 검색합니다.
- (ChatMemory가 제공된 경우) 이전 메시지를로드합니다.
- chatlanguagemodel에 대한 최종 프롬프트 (컨텍스트 및 기록 포함)를 구성합니다.
- LLM으로부터 응답을 얻습니다.
- (ChatMemory가 제공되는 경우) 현재 교환을 저장하십시오.
- LLM의 응답을 반환합니다.
5 단계 : 실행 및 테스트
- 환경 변수 설정 (OpenAI를 사용하는 경우): 당신을 확인하십시오
OPENAI_API_KEY환경 변수가 설정되었습니다. - Ollama 달리기 (Ollama를 사용하는 경우): Ollama 응용 프로그램이 백그라운드에서 실행되고 있는지 확인하십시오.
- 엮다: Maven을 사용하여 프로젝트를 컴파일하십시오 (예 : MVN Clean Compile).
- 달리다: 실행
KnowledgeAssistant수업. IDE에서 실행하거나 Maven을 사용하여 실행 가능한 JAR (MVN Clean 패키지)을 만들고 실행할 수 있습니다 (java -jar target/knowledge-base-chat-1.0-SNAPSHOT.jar).
일단 달리면 섭취 메시지와 “어시스턴트 : 안녕하세요!” 즉각적인. components.txt 및 knowledge.txt의 내용에 따라 질문을 해보십시오.
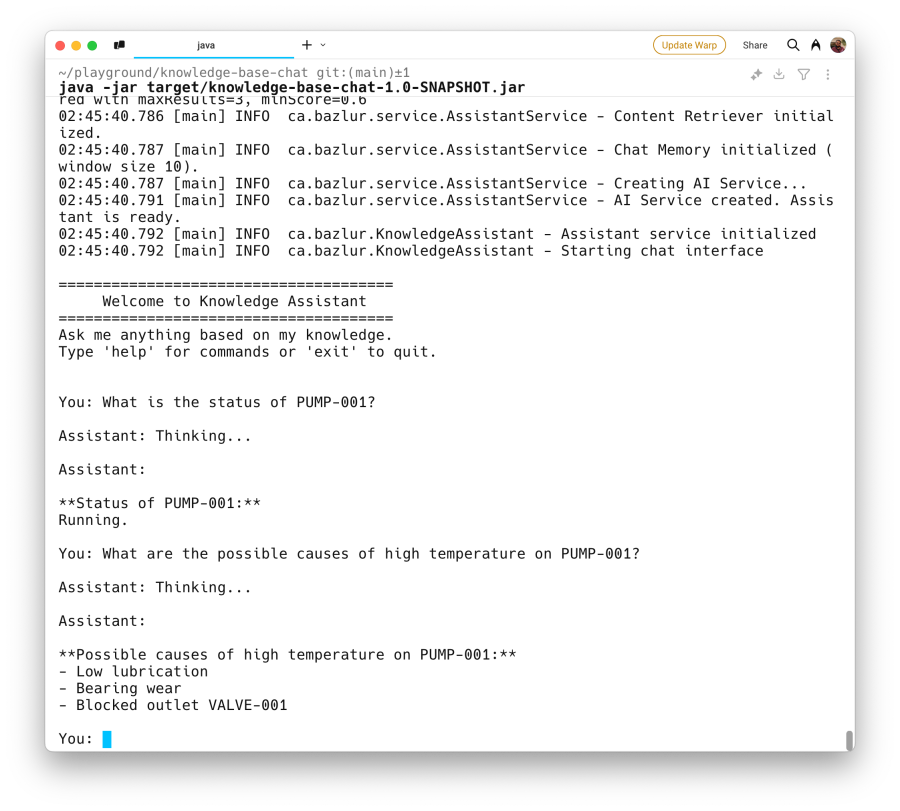
- 당신 : PUMP-001의 상태는 무엇입니까?
- 당신 : 센서 -P1은 어디에 있습니까?
- 당신 : 펌프 -001에서 고온의 가능한 원인은 무엇입니까?
- 당신 : 규칙 R001은 무엇입니까?
- 당신 : pump-001에 대해 말 해주세요.
- 당신 : 펌프 -001의 안전 절차는 무엇입니까?
어시스턴트의 답변이 텍스트 파일에 제공된 정보에서 어떻게 파생되는지 관찰하여 RAG 프로세스를 실행하는 것을 보여줍니다.
결론
축하해요! Java 및 Langchain4J를 사용하여 기본 검색 세대 생성 (RAG) 응용 프로그램을 구축했습니다. 사용자 정의 지식을로드하고 검색 가능한 임베딩으로 처리하는 방법을 보았 으며이 특정 정보를 활용하여 관련 답변을 제공하는 AI 어시스턴트를 만듭니다.
LLM의 힘을 도메인 별 데이터와 결합하는 이러한 접근 방식은 세상을 진정으로 이해하는 지능형 응용 프로그램을 구축 할 수있는 방대한 가능성을 열어줍니다.
자원
전체 소스 코드는 다음을 방문하십시오.
LLM을 Java와 통합하는 더 많은 예를 찾고 있다면, 특히 Jakarta EE 컨텍스트 내 에서이 저장소가 도움이 될 수 있습니다.










")


Post Comment