GitHub 문제 검색은 이제 중첩 쿼리 및 부울 연산자를 지원합니다. 여기에 우리가 구축 한 방법은 다음과 같습니다.

원래 문제 검색은 단순하고 평평한 쿼리 구조로 제한되었습니다. 그러나 Advanced Search Syntax를 사용하면 논리 및/또는 연산자 및 중첩 괄호를 사용하여 검색을 구성하여 정확한 문제를 정확히 찾아 낼 수 있습니다.
이 기능을 구축하면 기존 검색과의 역 호환성 보장, 높은 쿼리 볼륨에서 성능 유지, 중첩 검색에 대한 사용자 친화적 인 경험을 제작하는 중요한 과제가있었습니다. 우리는이 장기적인 기능을 아이디어에서 제작에 이르는 방법을 공유하기 위해 무대 뒤에서 당신을 데려 가게되어 기쁩니다.
새로운 구문으로 할 수있는 일과 무대 뒤에서 어떻게 작동하는지는 다음과 같습니다.
문제 검색은 이제 논리 및/또는 운영자와 함께 쿼리 구축을 지원합니다. 모두 쿼리 용어를 중첩 할 수있는 필드. 예를 들어 is:issue state:open author:rileybroughten (type:Bug OR type:Epic) 모든 것을 찾습니다 문제 그게 열려 있는 그리고 작가에드 라일리 브로 텐 그리고 유형입니다 벌레 또는 서사시.

우리는 어떻게 여기에 도착 했습니까?
이전에 언급 한 바와 같이, 문제 검색은 쿼리 필드 및 용어의 평평한 목록 만 지원했으며, 이는 논리적으로 암시 적으로 결합되었습니다. 예를 들어 쿼리입니다 assignee:@me label:support new-project “나에게 할당 된 모든 문제를주고 레이블을 가지고 있습니다. 지원하다 그리고 텍스트를 포함합니다 새로운 프로젝트.‘
그러나 개발자 커뮤니티는 거의 10 년 동안 문제 검색에 더 많은 유연성을 요구해 왔습니다. 그들은 가진 모든 문제를 찾을 수 있기를 원했습니다. 어느 하나 레이블 support 또는 레이블 question쿼리 사용 label:support OR label:question. 그래서 우리는 2021 년에 쉼표로 구분 된 값 목록을 사용하여 또는 스타일 검색을 활성화했을 때이 요청에 대한 향상을 선보였습니다.
그러나 그들은 여전히 이런 식으로 검색 할 수있는 유연성을 원했습니다. 모두 뿐만 아니라 필드를 발행합니다 라벨 필드. 그래서 우리는 일을 시작했습니다.
기술 아키텍처 및 구현
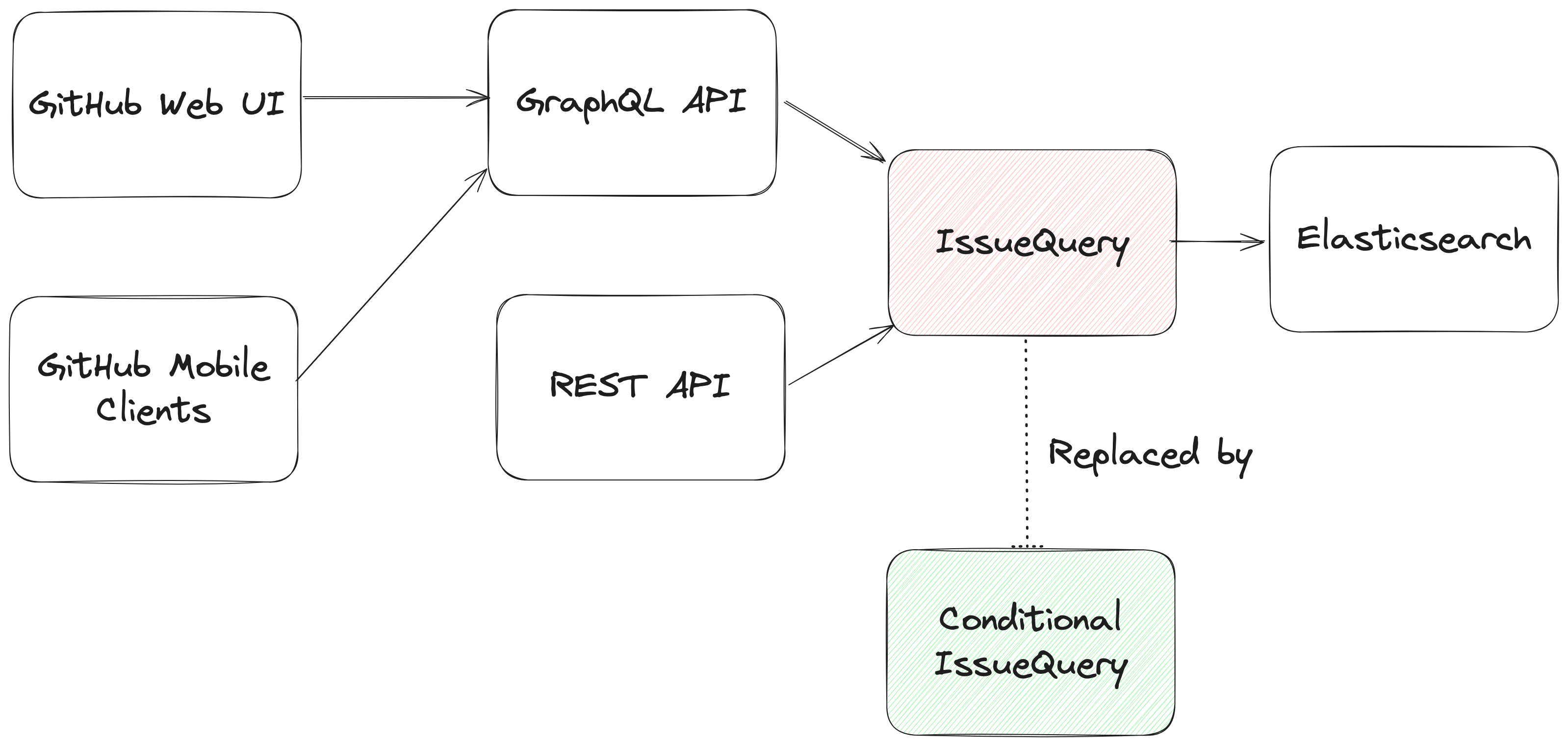
아키텍처 관점에서, 기존 쿼리 형식을 계속 지원하면서 중첩 쿼리를 처리 할 수있는 새로운 검색 모듈 (컨디셔스 쿼리)으로 기존 검색 모듈을 이슈 (IssuesQuery)에 대한 기존 검색 모듈을 교체했습니다.
여기에는 쿼리 문자열을 구문 분석하고 Elasticsearch 쿼리에 매핑하는 검색 모듈 인 IssureQuery를 다시 작성했습니다.

새 검색 모듈을 구축하려면 먼저 기존 검색 모듈과 단일 검색 쿼리가 시스템을 통해 유동되는 방법을 이해해야했습니다. 높은 수준에서 사용자가 검색을 수행 할 때 실행에는 세 단계가 있습니다.
- 구문 분석: 사용자 입력 문자열을 처리하기 쉬운 구조로 나누는 것 (목록이나 트리와 같이)
- 질문: 구문 분석 구조를 Elasticsearch 쿼리 문서로 변환하고 Elasticsearch에 대한 쿼리를 만듭니다.
- 정상화 : Elasticsearch (JSON)에서 얻은 결과를 Ruby 객체로 맵핑하여 쉽게 액세스 할 수 있도록 결과를 가지 치기 결과를 제거하여 데이터베이스에서 제거 된 레코드를 제거합니다.
각 단계는 고유 한 도전을 제시했으며 아래에서 더 자세히 살펴볼 것입니다. 그만큼 정상화하십시오 재 작성 중에 단계는 변경되지 않았으므로 우리는 그 중에 뛰어 들지 않을 것입니다.
구문 분석 단계
사용자 입력 문자열 (검색어)은 먼저 중간 구조로 구문 분석됩니다. 검색어에는 다음이 포함될 수 있습니다.
- 쿼리 용어 : 사용자가 더 많은 정보를 찾으려고하는 관련 단어 (예 :“모델”)
- 검색 필터 : 이들은 일부 기준에 따라 반환 된 검색 문서 세트를 제한합니다 (예 :“양수인 : Deborah-Digges”).
검색 문구 예 :
- “codespaces”라는 단어가 포함 된 모든 문제를 찾으십시오.
is:issue assignee:@me codespaces
- 레이블의 모든 문제를 찾으십시오 선적 서류 비치 나에게 할당 된 :
assignee:@me label:documentation
오래된 구문 분석 방법 : 평면 목록
평평하고 간단한 쿼리 만 지원되면 사용자의 검색 문자열을 검색어 및 필터 목록으로 구문 분석하는 것으로 충분했으며 검색 프로세스의 다음 단계로 전달됩니다.
새로운 구문 분석 방법 : 초록 구문 트리
중첩 된 쿼리가 재귀적일 수 있으므로 검색 문자열을 목록에 구문 분석하는 것만으로 더 이상 충분하지 않았습니다. 구문 분석 라이브러리 구문 분석을 사용하여 사용자의 검색 문자열을 AST (Abstract Syntax Tree)로 구문 분석하도록이 구성 요소를 변경했습니다.
검색 문자열의 구조를 나타 내기 위해 문법 (페그 또는 구문 분석 표현 문법)을 정의했습니다. 문법은 기존 쿼리 구문과 새로운 중첩 쿼리 구문을 모두 지원하여 후진 호환성을 허용합니다.
파르렛 파서에 대한 페그 문법에 의해 기술 된 부울 발현을위한 단순화 된 문법은 다음과 같습니다.
class Parser > space? }
rule(:rparen) { str(")") >> space? }
rule(:and_operator) { str("and") >> space? }
rule(:or_operator) { str("or") >> space? }
rule(:var) { str("var") >> match["0-9"].repeat(1).as(:var) >> space? }
# The primary rule deals with parentheses.
rule(:primary) { lparen >> or_operation >> rparen | var }
# Note that following rules are both right-recursive.
rule(:and_operation) {
(primary.as(:left) >> and_operator >>
and_operation.as(:right)).as(:and) |
primary }
rule(:or_operation) {
(and_operation.as(:left) >> or_operator >>
or_operation.as(:right)).as(:or) |
and_operation }
# We start at the lowest precedence rule.
root(:or_operation)
end예를 들어이 사용자 검색 문자열 :is:issue AND (author:deborah-digges OR author:monalisa )
다음과 같은 AST에 구문 분석됩니다.
{
"root": {
"and": {
"left": {
"filter_term": {
"attribute": "is",
"value": [
{
"filter_value": "issue"
}
]
}
},
"right": {
"or": {
"left": {
"filter_term": {
"attribute": "author",
"value": [
{
"filter_value": "deborah-digges"
}
]
}
},
"right": {
"filter_term": {
"attribute": "author",
"value": [
{
"filter_value": "monalisa"
}
]
}
}
}
}
}
}
}질문
쿼리가 중간 구조로 구문 분석되면 다음 단계는 다음과 같습니다.
- 이 중간 구조를 Elasticsearch가 이해하는 쿼리 문서로 변환합니다.
- elasticsearch에 대해 쿼리를 실행하여 결과를 얻습니다
2 단계에서 쿼리를 실행하는 것은 이전 시스템과 새 시스템 사이에서 동일하게 유지되었으므로 아래 쿼리 문서를 작성하는 데 있어만 차이를 살펴 보겠습니다.
기존 쿼리 생성 : 필터 클래스를 사용한 필터 항의 선형 매핑
각 필터 용어 (예 : label:documentation)에는 Elasticsearch 쿼리 문서의 스 니펫으로 변환하는 방법을 알고있는 클래스가 있습니다. 쿼리 문서 생성 중에는 각 필터 용어에 대한 올바른 클래스가 호출되어 전체 쿼리 문서를 구성합니다.
새로운 쿼리 생성 : elasticsearch bool 쿼리 생성을위한 재귀 AST 트래버스
우리는 구문 분석 중에 생성 된 AST를 재귀 적으로 통과하여 동등한 Elasticsearch Query 문서를 작성했습니다. 중첩 된 구조와 부울 연산자는 Elasticsearch의 부울 쿼리에 훌륭하게 매핑됩니다. ~ 해야 하다,,, ~해야 한다그리고 해야 할 것입니다 조항.
작은 쿼리 생성물에 대한 빌딩 블록을 재사용하여 트리 트래버스 동안 중첩 쿼리 문서를 재귀 적으로 구성했습니다.
구문 분석 단계의 예에서 계속해서 AST는 다음과 같은 쿼리 문서로 변환됩니다.
{
"query": {
"bool": {
"must": [
{
"bool": {
"must": [
{
"bool": {
"must": {
"prefix": {
"_index": "issues"
}
}
}
},
{
"bool": {
"should": {
"terms": {
"author_id": [
"",
""
]
}
}
}
}
]
}
}
]
}
// SOME TERMS OMITTED FOR BREVITY
}
} 이 새로운 쿼리 문서를 사용하면 Elasticsearch에 대한 검색을 실행합니다. 이 검색은 이제 논리 및/또는 연산자 및 괄호를 지원하여보다 세밀한 방식으로 문제를 검색합니다.
고려 사항
문제는 Github에서 가장 오래되고 가장 많이 사용되는 기능 중 하나입니다. QP (QPS) 평균 거의 2000 쿼리의 기능인 문제 검색과 같은 핵심 기능을 변경하여 하루에 거의 160m 쿼리입니다!
후진 호환성 보장
문제 검색은 종종 북마크, 사용자간에 공유되며 문서에 연결되어 개발자와 팀에게 중요한 유물을 만듭니다. 따라서 사용자를위한 기존 쿼리를 깨지 않고 중첩 검색 쿼리에 대한이 새로운 기능을 소개하려고했습니다.
사용자에게 도달하기 전에 새로운 검색 시스템을 검증했습니다.
- 광범위하게 테스트: 기존 검색 모듈에 대한 모든 장치 및 통합 테스트에 대해 새 검색 모듈을 실행했습니다. GraphQL 및 REST API 계약이 변경되지 않은 상태로 유지되도록 새로운 검색 시스템을 활성화하고 비활성화하는 기능 플래그와 함께 검색 엔드 포인트에 대한 테스트를 실행했습니다.
- 어두운 곳으로 생산의 정확성 검증 : 문제 검색의 1%의 경우 백그라운드 작업에서 기존 및 새 검색 시스템에 대한 사용자의 검색을 실행하고 응답의 차이를 기록했습니다. 이러한 차이점을 분석함으로써 우리는 버그가 사용자에게 도달하기 전에 버그를 수정할 수있었습니다.
- 우리는 처음에“차이”를 정의하는 방법을 확신하지 못했지만 첫 번째 반복에 대한“결과 수”를 해결했습니다. 일반적으로 검색이 서로 다른 수 이내에 실행될 때 다른 수의 결과를 반환하면 새로운 검색 기능에 대한 검색 결과에 사용자가 놀라게 될지 여부를 결정할 수있는 것처럼 보였습니다.
성능 저하 방지
우리는 더 복잡한 중첩 쿼리가 더 간단한 쿼리보다 백엔드에서 더 많은 리소스를 사용할 것으로 예상 했으므로 중첩 쿼리에 대한 현실적인 기준선을 설정하면서 기존의 단순한 쿼리의 성능에 대한 회귀를 보장해야했습니다.
이슈 검색의 1%의 경우 기존 검색 시스템과 새 검색 시스템 모두에 대해 동등한 쿼리를 실행했습니다. 우리는 과학자 인 Github의 오픈 소스 Ruby Library를 사용하여 계급 경로를 신중하게 리팩토링하여 동등한 쿼리의 성능을 비교하여 회귀가 없는지 확인했습니다.
사용자 경험을 보존합니다
우리는 더 복잡한 검색이 있었기 때문에 사용자가 이전보다 더 나쁜 경험을하기를 원하지 않았습니다. 가능한.
우리는이 기능을 추가하여 제품 및 디자인 팀과 긴밀히 협력하여 유용성이 감소하지 않도록했습니다.
- 중첩 레벨 수를 제한합니다 쿼리에서 5 개. 고객 인터뷰에서 우리는 이것이 유용성과 유용성 모두에 대한 달콤한 장소라는 것을 알았습니다.
- 유용한 UI/UX 큐를 제공합니다: 검색 쿼리의 및/또는 키워드를 강조 표시하고, UI의 필터 용어에 대한 동일한 자동 완성 기능을 사용자에게 간단한 플랫 쿼리에 익숙한 동일한 자동 완성 기능을 제공합니다.
기존 사용자에 대한 위험을 최소화합니다
하루에 수백만 명의 사용자가 사용하는 기능의 경우 사용자에게 위험을 최소화하는 방식으로이를 롤아웃하는 데 의도적이어야했습니다.
우리는 다음과 같이 시스템에 대한 자신감을 쌓았습니다.
- 폭발 반경 제한: 점차 신뢰를 구축하기 위해, 우리는 새로운 시스템을 GraphQL API에만 통합하고 UI의 저장소에 대한 문제 탭을 시작했습니다. 이를 통해 모든 소비자에게 저하 된 경험을 위험에 빠뜨리지 않고 수집, 응답 및 피드백을 통합 할 시간을주었습니다. 우리가 그 성능에 만족했을 때, 우리는 그것을 대시 보드와 나머지 API로 롤아웃했습니다.
- 내부 및 신뢰할 수있는 파트너와 테스트: GitHub에서 구축 한 모든 기능과 마찬가지로, 우리는 초기에 팀에 배송하여 개발 기간 동안 내부적 으로이 기능을 테스트 한 다음 점차 Github 직원에게 롤아웃했습니다. 그런 다음 초기 사용자 피드백을 수집하기 위해 신뢰할 수있는 파트너에게 배송했습니다.
그리고 거기에 당신은 그것을 가지고 있습니다. 그것이 우리가 새롭고 개선 된 문제 검색을 구축, 검증 및 배송하는 방식입니다!
피드백
이 흥미 진진한 새로운 기능을 시험해보고 싶습니까? DOCS로 가서 부울 운영자와 괄호를 사용하여 관심있는 문제를 검색하는 방법에 대해 알아보십시오!
이 기능에 대한 피드백이 있으면 커뮤니티 토론에 대한 메모를 보내주십시오.
감사의 말
AJ Schuster, Riley Broughten, Stephanie Goldstein, Eric Jorgensen Mike Melanson 및 Laura Lindeman 에게이 블로그 게시물의 여러 반복에 대한 특별한 감사를드립니다!
작성자가 작성했습니다













")
Post Comment