DeepSeek R1 – OpenAI의 o1 최대 경쟁자가 여기에 있습니다!

DeepSeek AI는 매우 기대되는 DeepSeek R1 추론 모델을 출시하여 생성 인공 지능 세계에 새로운 표준을 설정했습니다. 강화 학습(RL)과 오픈 소스 정신에 중점을 둔 DeepSeek-R1은 전 세계 연구원과 개발자가 액세스할 수 있는 동시에 고급 추론 기능을 제공합니다. 이 모델은 OpenAI의 o1 모델과 경쟁하도록 설정되어 있으며 실제로 여러 벤치마크에서 동일한 성능을 능가했습니다. DeepSeek R1을 사용하면 많은 사람들이 이것이 Open AI LLM 패권의 종말인지 궁금해하게 만들었습니다. 더 자세히 읽어 보도록 하겠습니다!
DeepSeek R1이란 무엇입니까?
DeepSeek-R1은 고급 강화 학습(RL) 기법을 통해 생성 AI 시스템의 추론 능력을 향상시키기 위해 개발된 추론 중심의 대형 언어 모델(LLM)입니다.
- 이는 특히 사전 단계로 감독 미세 조정(SFT)에 크게 의존하지 않고 LLM의 추론을 향상시키는 중요한 단계를 나타냅니다.
- 기본적으로 DeepSeek-R1은 SFT(감독 미세 조정)에 크게 의존하지 않고 추론을 향상시키는 AI의 주요 과제를 해결합니다.
혁신적인 훈련 방법론은 모델이 수학, 코딩, 논리와 같은 복잡한 작업을 처리할 수 있도록 지원합니다.

또한 읽어 보세요: Andrej Karpathy는 600만 달러의 예산으로 교육받은 DeepSeek V3의 Frontier LLM을 칭찬합니다.
DeepSeek-R1: 훈련
1. 강화 학습
- DeepSeek-R1-Zero는 SFT 없이 강화 학습(RL)만을 사용하여 훈련됩니다. 이 독특한 접근 방식은 모델이 자체 검증, 반성 및 CoT(사고 사슬) 추론과 같은 고급 추론 기능을 자율적으로 개발하도록 장려합니다.
보상 디자인
- 시스템은 작업별 벤치마크를 기반으로 추론 정확도에 대한 보상을 할당합니다.
- 또한 구조화되고 읽기 가능하며 일관된 추론 출력에 대한 2차 보상을 제공합니다.
거부 샘플링
- RL 중에는 여러 추론 궤적이 생성되고 가장 성능이 좋은 궤적이 선택되어 훈련 프로세스를 추가로 안내합니다.
2. 사람이 주석을 추가한 데이터를 사용한 콜드 스타트 초기화
- DeepSeek-R1의 경우 인간이 주석을 추가한 긴 CoT 추론의 예를 사용하여 훈련 파이프라인을 초기화합니다. 이를 통해 가독성이 향상되고 사용자 기대에 부응할 수 있습니다.
- 이 단계는 순수 RL 학습(단편화되거나 모호한 출력으로 이어질 수 있음)과 고품질 추론 출력 간의 격차를 해소합니다.
3. 다단계 훈련 파이프라인
- 1단계: 콜드 스타트 데이터 사전 훈련: 선별된 인간 주석 데이터 세트는 기본 추론 구조로 모델을 준비합니다.
- 2단계: 강화 학습: 이 모델은 RL 작업을 처리하여 정확성, 일관성 및 정렬에 대한 보상을 얻습니다.
- 3단계: 거부 샘플링을 통한 미세 조정: 시스템은 RL의 출력을 미세 조정하고 최상의 추론 패턴을 강화합니다.
4. 증류
- 이 파이프라인으로 훈련된 대규모 모델은 더 작은 버전으로 정제되어 추론 성능을 유지하면서 계산 비용을 대폭 절감합니다.
- 증류된 모델은 심각한 성능 저하 없이 DeepSeek-R1과 같은 더 큰 모델의 기능을 상속합니다.
DeepSeek R1: 모델
DeepSeek R1에는 2개의 코어 모델과 6개의 증류 모델이 함께 제공됩니다.
핵심 모델
DeepSeek-R1-제로
감독된 미세 조정 없이 기본 모델에서 강화 학습(RL)을 통해서만 훈련되었습니다. 자체 검증 및 반성과 같은 고급 추론 동작을 보여 주며 다음과 같은 벤치마크에서 주목할만한 결과를 달성합니다.
과제: 콜드 스타트 데이터 및 구조화된 미세 조정 부족으로 인해 가독성 및 언어 혼합에 어려움을 겪고 있습니다.
DeepSeek-R1
강화된 초기화를 위해 콜드 스타트 데이터(사람이 주석을 단 긴 CoT(긴 사고 사슬) 예제)를 통합하여 DeepSeek-R1-Zero를 기반으로 합니다. 인간의 선호.
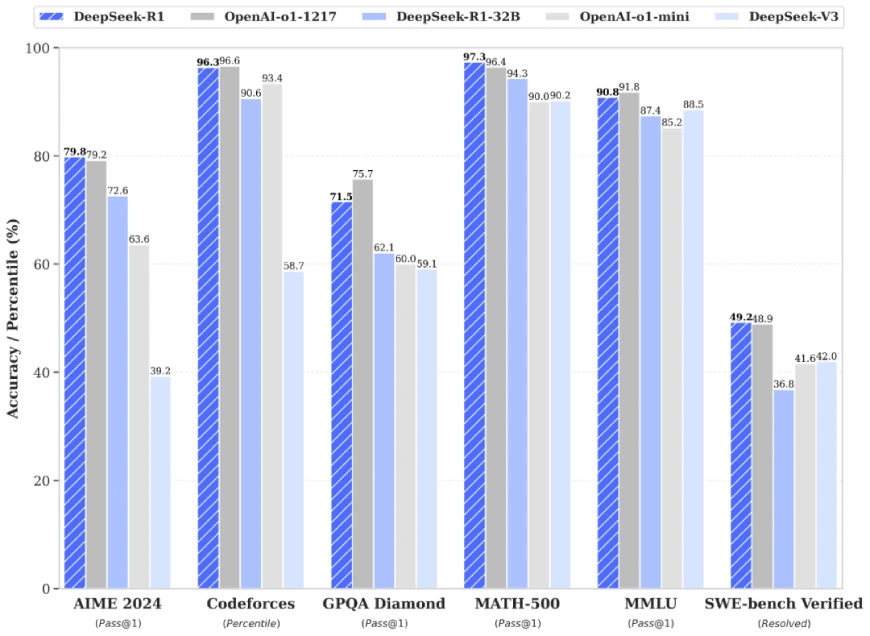
OpenAI의 o1-1217과 직접 경쟁하여 다음을 달성합니다.
- AIME 2024: Pass@1 점수는 79.8%로 o1-1217을 약간 능가합니다.
- MATH-500: Pass@1 점수는 97.3%이며 o1-1217과 동일합니다.
지식 집약적이고 STEM 관련 작업은 물론 코딩 문제에도 탁월합니다.
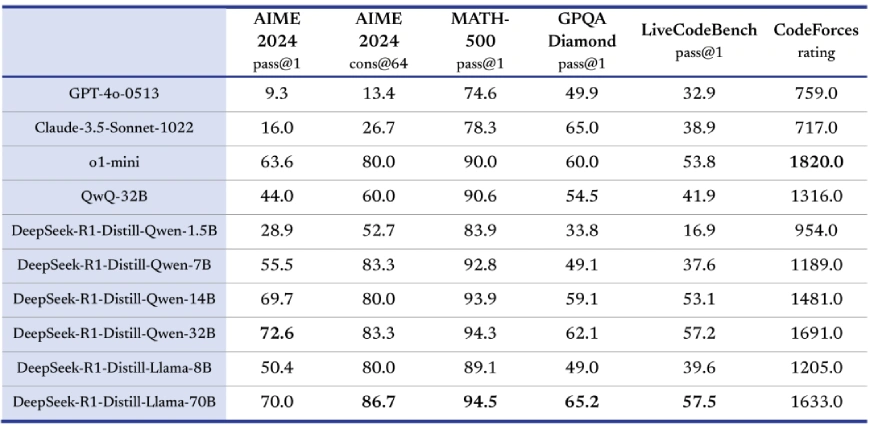
증류된 모델
획기적인 움직임으로 DeepSeek-AI는 R1 모델의 증류 버전도 출시하여 더 작고 계산적으로 효율적인 모델이 더 큰 모델의 추론 능력을 상속하도록 보장합니다. 이러한 증류 모델에는 다음이 포함됩니다.
이러한 소형 모델은 QwQ-32B-Preview와 같은 오픈 소스 경쟁사보다 성능이 뛰어나며 OpenAI의 o1-mini와 같은 독점 모델과 효과적으로 경쟁합니다.
DeepSeek R1: 주요 특징
DeepSeek-R1 모델은 업계에서 가장 발전된 LLM과 경쟁할 수 있도록 설계되었습니다. AIME 2024, MATH-500 및 Codeforces와 같은 벤치마크에서 DeepSeek-R1은 OpenAI의 o1-1217 및 Anthropic의 Claude Sonnet 3과 비교할 때 경쟁력이 있거나 우수한 성능을 보여줍니다.
- AIME 2024(패스@1)
- MATH-500
- 코드포스
고성능 외에도 DeepSeek-R1의 오픈 소스 가용성은 독점 모델에 대한 비용 효율적인 대안으로 자리매김하여 채택 장벽을 낮춥니다.
R1에 액세스하는 방법?
웹 액세스
프리미엄 가격을 지불해야 하는 OpenAI의 o1과 달리 DeepSeek은 R1 모델을 모든 사람이 채팅 인터페이스에서 무료로 사용해 볼 수 있도록 만들었습니다.
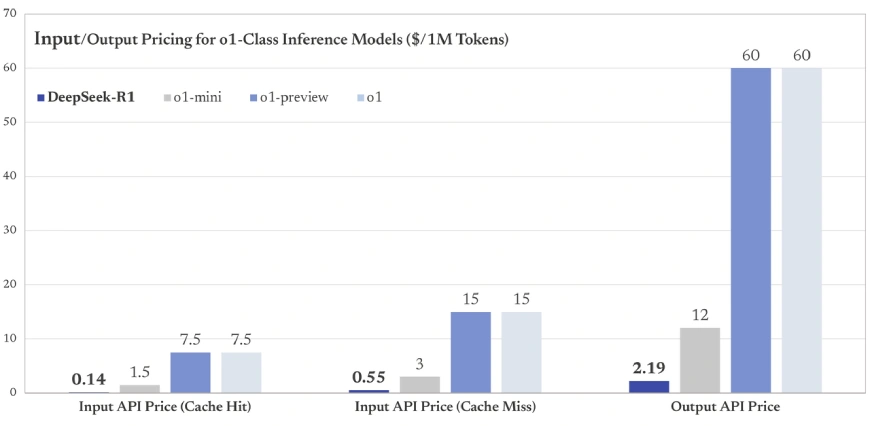
API 액세스
여기에서 해당 API에 액세스할 수 있습니다.
캐시 히트에 대한 기본 입력 비용이 백만 토큰당 $0.14인 DeepSeek-R1은 많은 독점 모델보다 훨씬 저렴합니다(예: OpenAI GPT-4 입력 비용은 1K 토큰당 $0.03 또는 백만 토큰당 $30부터 시작).
응용
- STEM 교육: 수학 중심 벤치마크에서 탁월한 성능을 발휘하는 이 모델은 교육자와 학생이 복잡한 문제를 해결하는 데 도움이 될 수 있습니다.
- 코딩 및 소프트웨어 개발: Codeforces 및 LiveCodeBench와 같은 플랫폼에서 고성능을 제공하는 DeepSeek-R1은 개발자를 지원하는 데 이상적입니다.
- 일반 지식 작업: GPQA Diamond와 같은 벤치마크에서의 탁월함은 사실 기반 추론을 위한 강력한 도구로 자리매김합니다.
또한 읽어보세요:
끝 메모
DeepSeek-AI는 증류된 버전을 포함한 DeepSeek-R1 모델 제품군을 오픈 소스화함으로써 더 광범위한 AI 커뮤니티가 액세스할 수 있는 고품질 추론 기능을 만들고 있습니다. 이 이니셔티브는 액세스를 민주화할 뿐만 아니라 협업과 혁신을 촉진합니다.
AI 환경이 발전함에 따라 DeepSeek-R1은 오픈 소스 유연성과 최첨단 성능 간의 격차를 해소하는 진보의 신호탄으로 두각을 나타내고 있습니다. 산업 전반에 걸쳐 추론 작업을 재구성할 수 있는 잠재력을 갖춘 DeepSeek-AI는 AI 혁명의 핵심 플레이어가 될 준비가 되어 있습니다.
Analytics Vidhya News에 대한 추가 업데이트를 계속 지켜봐 주시기 바랍니다!
![]()
Anu Madan은 콘텐츠 제작 및 관리 분야에서 5년 이상의 경험을 보유하고 있습니다. 콘텐츠 제작자, 리뷰어, 관리자로 일하면서 여러 강좌와 블로그를 만들었습니다. 현재 그녀는 Generative AI 및 기타 향후 기술을 중심으로 콘텐츠 큐레이션과 디자인을 만들고 전략화하는 작업을 하고 있습니다.












Post Comment