langgraph 반사로 코드 품질 향상

Langgraph Reflection Framework는 생성 AI를 사용하여 반복적 인 비판 프로세스를 통해 언어 모델 출력을 향상시키는 강력한 방법을 제공하는 에이전트 프레임 워크의 한 유형입니다. 이 기사는 해석을 사용하여 파이썬 코드를 검증하는 반사제를 구현하는 방법을 세분화하고 GPT-4O 미니를 사용하여 품질을 향상시킵니다. AI 에이전트는이 프레임 워크에서 중요한 역할을하며, 추론, 반사 및 피드백 메커니즘을 결합하여 모델 성능을 향상시켜 의사 결정 프로세스를 자동화합니다.
학습 목표
- Langgraph Reflection Framework가 어떻게 작동하는지 이해하십시오.
- 파이썬 코드의 품질을 향상시키기 위해 프레임 워크를 구현하는 방법을 알아보십시오.
- 실습 시험을 통해 프레임 워크가 얼마나 잘 작동하는지 경험하십시오.
이 기사는의 일부로 출판되었습니다 데이터 과학 블로그.
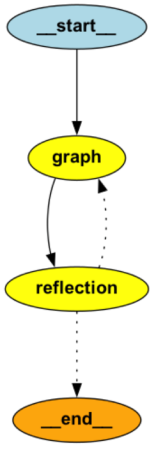
langgraph 반사 프레임 워크 아키텍처
Langgraph Reflection Framework는 간단하면서도 효과적인 에이전트 아키텍처를 따릅니다.
- 메인 에이전트: 사용자의 요청에 따라 초기 코드를 생성합니다.
- 대리인: 배열을 사용하여 생성 된 코드를 확인합니다.
- 반사 과정: 오류가 감지되면 문제가 남아있을 때까지 메인 에이전트가 다시 코드를 개선하기 위해 호출됩니다.
또한 읽기 : 생성 AI 응용 프로그램을위한 에이전트 프레임 워크
langgraph 반사 프레임 워크를 구현하는 방법
여기에 있습니다 단계별 가이드 예시적인 구현 및 사용을 위해 :
1 단계 : 환경 설정
먼저 필요한 종속성을 설치하십시오.
pip install langgraph-reflection langchain pyright2 단계 : 배열을 통한 코드 분석
발언을 사용하여 생성 된 코드를 분석하고 오류 세부 정보를 제공합니다.
배열 분석 기능
from typing import TypedDict, Annotated, Literal
import json
import os
import subprocess
import tempfile
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph_reflection import create_reflection_graph
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
def analyze_with_pyright(code_string: str) -> dict:
"""Analyze Python code using Pyright for static type checking and errors.
Args:
code_string: The Python code to analyze as a string
Returns:
dict: The Pyright analysis results
"""
with tempfile.NamedTemporaryFile(suffix=".py", mode="w", delete=False) as temp:
temp.write(code_string)
temp_path = temp.name
try:
result = subprocess.run(
[
"pyright",
"--outputjson",
"--level",
"error", # Only report errors, not warnings
temp_path,
],
capture_output=True,
text=True,
)
try:
return json.loads(result.stdout)
except json.JSONDecodeError:
return {
"error": "Failed to parse Pyright output",
"raw_output": result.stdout,
}
finally:
os.unlink(temp_path)3 단계 : 코드 생성을위한 주요 보조 모델
GPT-4O 미니 모델 설정
def call_model(state: dict) -> dict:
"""Process the user query with the GPT-4o mini model.
Args:
state: The current conversation state
Returns:
dict: Updated state with the model response
"""
model = init_chat_model(model="gpt-4o-mini", openai_api_key = 'your_openai_api_key')
return {"messages": model.invoke(state["messages"])}참고 : 사용 os.environ[“OPENAI_API_KEY”] =“your_api_key”단단히, 코드에서 키를 하드 코딩하지 마십시오.
4 단계 : 코드 추출 및 검증
코드 추출 유형
# Define type classes for code extraction
class ExtractPythonCode(TypedDict):
"""Type class for extracting Python code. The python_code field is the code to be extracted."""
python_code: str
class NoCode(TypedDict):
"""Type class for indicating no code was found."""
no_code: boolGPT-4O MINI의 시스템 프롬프트
# System prompt for the model
SYSTEM_PROMPT = """The below conversation is you conversing with a user to write some python code. Your final response is the last message in the list.
Sometimes you will respond with code, othertimes with a question.
If there is code - extract it into a single python script using ExtractPythonCode.
If there is no code to extract - call NoCode."""화해 코드 유효성 검사 기능
def try_running(state: dict) -> dict | None:
"""Attempt to run and analyze the extracted Python code.
Args:
state: The current conversation state
Returns:
dict | None: Updated state with analysis results if code was found
"""
model = init_chat_model(model="gpt-4o-mini")
extraction = model.bind_tools([ExtractPythonCode, NoCode])
er = extraction.invoke(
[{"role": "system", "content": SYSTEM_PROMPT}] + state["messages"]
)
if len(er.tool_calls) == 0:
return None
tc = er.tool_calls[0]
if tc["name"] != "ExtractPythonCode":
return None
result = analyze_with_pyright(tc["args"]["python_code"])
print(result)
explanation = result["generalDiagnostics"]
if result["summary"]["errorCount"]:
return {
"messages": [
{
"role": "user",
"content": f"I ran pyright and found this: {explanation}\n\n"
"Try to fix it. Make sure to regenerate the entire code snippet. "
"If you are not sure what is wrong, or think there is a mistake, "
"you can ask me a question rather than generating code",
}
]
}5 단계 : 반사 그래프 작성
메인 및 판사 그래프 구축
def create_graphs():
"""Create and configure the assistant and judge graphs."""
# Define the main assistant graph
assistant_graph = (
StateGraph(MessagesState)
.add_node(call_model)
.add_edge(START, "call_model")
.add_edge("call_model", END)
.compile()
)
# Define the judge graph for code analysis
judge_graph = (
StateGraph(MessagesState)
.add_node(try_running)
.add_edge(START, "try_running")
.add_edge("try_running", END)
.compile()
)
# Create the complete reflection graph
return create_reflection_graph(assistant_graph, judge_graph).compile()
reflection_app = create_graphs()6 단계 : 응용 프로그램 실행
예제 실행
if __name__ == "__main__":
"""Run an example query through the reflection system."""
example_query = [
{
"role": "user",
"content": "Write a LangGraph RAG app",
}
]
print("Running example with reflection using GPT-4o mini...")
result = reflection_app.invoke({"messages": example_query})
print("Result:", result)출력 분석


예에서 무슨 일이 있었습니까?
우리의 langgraph 반사 시스템은 다음을 수행하도록 설계되었습니다.
- 초기 코드 스 니펫을 사용하십시오.
- 오류를 감지하기 위해 격언 (파이썬의 정적 유형 체크 머신)을 실행하십시오.
- GPT-4O 미니 모델을 사용하여 오류를 분석하고 이해하며 개선 된 코드 제안을 생성하십시오.
반복 1 – 식별 오류
1. “FAISS”가져 오기를 해결할 수 없습니다.
- 설명: 이 오류는 FAISS 라이브러리가 설치되지 않았거나 Python 환경이 가져 오기를 인식하지 못하는 경우에 발생합니다.
- 해결책: 에이전트는 달리기를 권장합니다.
pip install faiss-cpu2. “OpenAiembeddings”클래스의 속성에 “embed”에 액세스 할 수 없습니다.
- 설명: 코드는 .Embed를 참조했지만 최신 버전의 Langchain에서 포함 된 메소드는 .embed_documents () 또는 .embed_query ()입니다.
- 해결책: 에이전트는 .Embed_Query로 .Embed를 올바르게 교체했습니다.
3. 매개 변수 “docstore”, “index_to_docstore_id”에 대한 인수가 누락되었습니다.
- 설명: Faiss Vector Store에는 이제 docstore 객체와 index_to_docstore_id 매핑이 필요합니다.
- 해결책: 에이전트는 InmemoryDocstore와 사전 매핑을 만들어 두 매개 변수를 추가했습니다.
반복 2 – 진행
두 번째 반복에서 시스템은 코드를 개선했지만 여전히 식별했습니다.
1. “langchain.document”가져 오기를 해결할 수 없습니다.
- 설명: 코드는 잘못된 모듈에서 문서를 가져 오려고 시도했습니다.
- 해결책: 에이전트는 수입을 Langchain.docstore 가져 오기 문서로 업데이트했습니다.
2.“InmemoryDocstore”는 정의되지 않았습니다.
- 설명: InmemoryDocstore의 누락 된 수입이 확인되었습니다.
- 해결책: 에이전트가 올바르게 추가되었습니다.
from langchain.docstore import InMemoryDocstore반복 3 – 최종 솔루션
최종 반복에서 반사제는 모든 문제를 다음과 같이 성공적으로 해결했습니다.
- Faiss를 올바르게 가져옵니다.
- 임베딩 함수를 위해 .embed_query로 .embed를 전환합니다.
- 문서 관리를 위해 유효한 InMemoryDocstore 추가.
- 적절한 index_to_docstore_id 매핑 생성.
- 문서를 간단한 문자열로 취급하는 대신 .page_content를 사용하여 문서 컨텐츠에 올바르게 액세스하십시오.
개선 된 코드는 오류없이 성공적으로 실행되었습니다.
이것이 중요한 이유
- 자동 오류 감지 : Langgraph Reflection Framework는 계약을 사용하여 코드 오류를 분석하고 실행 가능한 통찰력을 생성하여 디버깅 프로세스를 단순화합니다.
- 반복 개선 : 프레임 워크는 오류가 해결 될 때까지 코드를 지속적으로 개선하여 개발자가 수동으로 디버깅하고 코드를 개선 할 수있는 방법을 모방합니다.
- 적응 학습 : 시스템은 업데이트 된 라이브러리 구문 또는 버전 차이와 같은 변경된 코드 구조에 적응합니다.
결론
Langgraph Reflection Framework는 AI 비평가를 강력한 정적 분석 도구와 결합하는 힘을 보여줍니다. 이 지능형 피드백 루프는 더 빠른 코드 보정, 개선 된 코딩 관행 및 전반적인 개발 효율성을 높일 수 있습니다. 초보자 또는 숙련 된 개발자이든 Langgraph Reflection은 코드 품질을 향상시키는 강력한 도구를 제공합니다.
주요 테이크 아웃
- Langgraph Reflection Framework 내에서 Langchain, Vyright 및 GPT-4O Mini를 결합 하여이 솔루션은 코드를 자동으로 검증하는 효과적인 방법을 제공합니다.
- 이 프레임 워크는 LLM이 반복적으로 개선 된 솔루션을 생성하고 반사 및 비판주기를 통해 고품질 출력을 보장합니다.
- 이 접근법은 AI 생성 코드의 견고성을 향상시키고 실제 시나리오에서 성능을 향상시킵니다.
이 기사에 표시된 미디어는 분석 Vidhya가 소유하지 않으며 저자의 재량에 따라 사용됩니다.
자주 묻는 질문
A. Langgraph Reflection은 1 차 AI 에이전트 (코드 생성 또는 작업 실행의 경우)와 비평 에이전트를 결합한 강력한 프레임 워크입니다 (문제를 식별하고 개선을 제안하기 위해). 이 반복 루프는 피드백과 반사를 활용하여 최종 출력을 향상시킵니다.
A. 반사 메커니즘은이 워크 플로를 따릅니다.
– 메인 에이전트 : 초기 출력을 생성합니다.
– 요원 비평가 : 오류 또는 개선에 대한 생성 된 출력을 분석합니다.
– 개선 루프 : 문제가 발견되면 주제에 대한 피드백이 다시 침입됩니다. 이 루프는 출력이 품질 표준을 충족 할 때까지 계속됩니다.
A. 다음의 종속성이 필요합니다.
-langgraph- 반사
– 랑케인
– 배열 (코드 분석 용)
– Faiss (벡터 검색 용)
-OpenAi (GPT 기반 모델 용)
설치하려면 실행 : PIP 설치 langgraph-reflection langchain vyright faiss openai
A. Langgraph Reflection은 다음과 같은 작업에서 탁월합니다.
– 파이썬 코드 검증 및 개선.
-사실 확인이 필요한 자연 언어 반응.
– 명확성과 완전성을 가진 문서 요약.
-AI 생성 컨텐츠가 안전 지침을 준수하도록합니다.
A. 아니요, 코드 수정 예제에서 발언을 표시했지만 프레임 워크는 텍스트 요약, 데이터 검증 및 챗봇 응답 개선을 개선하는 데 도움이 될 수 있습니다.
![]()
안녕! 저는 ISB를 졸업 한 비즈니스 분석 졸업생 인 Adarsh이며 현재 연구에 깊이 생각하고 새로운 프론티어를 탐구하고 있습니다. 저는 데이터 과학, AI 및 산업을 변화시킬 수있는 모든 혁신적인 방법에 대해 매우 열정적입니다. 모델을 구축하거나 데이터 파이프 라인 작업을하거나 머신 러닝에 뛰어 들든 최신 기술을 실험하는 것을 좋아합니다. AI는 내 관심만이 아니라 미래의 제목을 보는 곳이며, 나는 항상 그 여정의 일부가되어 기쁘게 생각합니다!
계속해서 읽고 전문가가 구축 된 콘텐츠를 즐기십시오.












: 아우라 카버부터 아우라 잉크까지")
Post Comment