Github Copilot은 코드를 찾는 데 더 똑똑해집니다 : 새로운 임베딩 모델 내부

올바른 코드를 빨리 찾는 것이 중요합니다. 커뮤니티의 피드백을 듣고 나면 코드 검색을 더 빠르게, 메모리에서 더 가볍고 훨씬 정확하게 검색 할 수있는 새로운 Copilot 임베딩 모델을 출시했습니다. 이것은 거의 미스 대신 실제로 필요한 스 니펫을 검색하는 것을 의미합니다. a 검색 품질이 37.6% 증가합니다~에 대한 2 배 높은 처리량그리고 an 8 배 작은 인덱스 크기따라서 GitHub Copilot 채팅 및 에이전트 응답이 더 정확하고 결과가 더 빠르며 VS 코드에서의 메모리 사용이 더 낮습니다.
이것이 중요한 이유
훌륭한 AI 코딩 경험은 올바른 컨텍스트를 찾는 데 달려 있습니다 : 스 니펫, 기능, 테스트, 문서 및 버그는 의도에 맞는 코드의 버그입니다. “찾기”단계는 정확한 단어가 일치하지 않더라도 의미 적으로 관련된 코드 및 자연어 내용을 검색하는 벡터 표현 인 임베딩으로 구동됩니다.
더 나은 임베딩은 검색 품질을 향상시키고 더 나은 Github Copilot 경험을 초래합니다.
우리가 배송 한 것
코드 및 문서에 맞게 조정 된 새로운 임베딩 모델을 교육하고 배포했습니다. 이제 에이전트, 편집 및 Ask 모드와 함께 Github Copilot Chat의 컨텍스트 검색에 전력을 공급합니다.
영향:
- 검색 품질 향상: +37.6% 다중 벤치 마크 평가에서 상대 리프트 (평균 점수는 0.362에서 0.498로 향상됨) (그림 1). C# VS Code의 C# 개발자의 경우 a를 보았습니다 +110.7% 코드 수락 비율을 높이고 Java 개발자에게는 +113.1% 코드 수용 비율을 높이십시오.
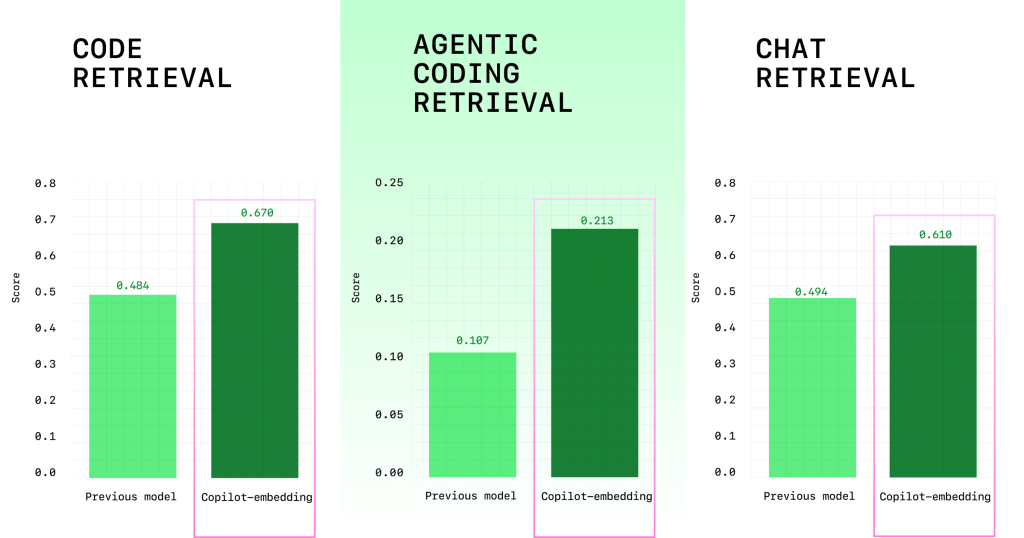
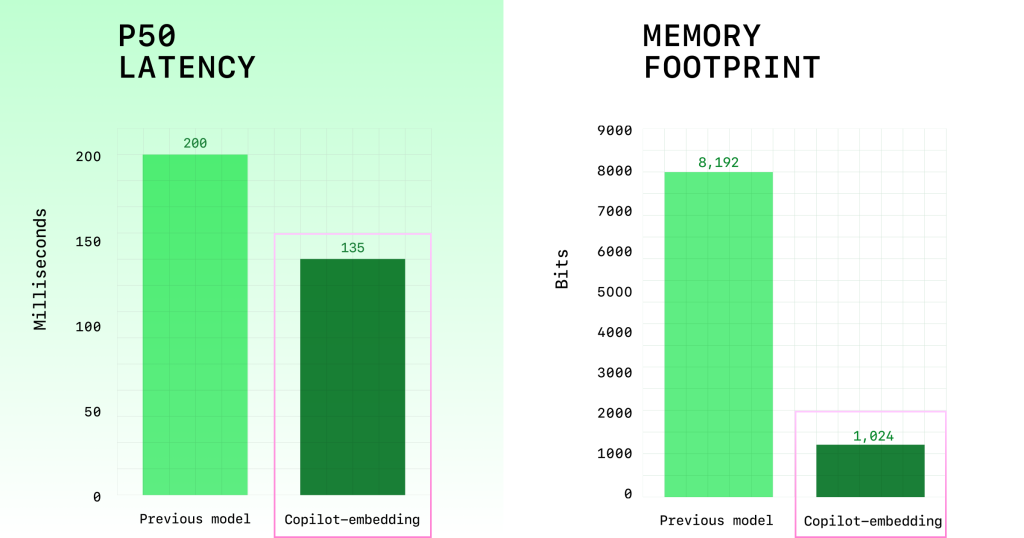
- 더 큰 효율성 : ~ 2x 임베딩 처리량이 높을수록 검색 대기 시간이 줄어들고 (그림 2), ~ 8 배 작은 인덱스 메모리 크기가 클라이언트와 서버의 스케일링을 향상시킵니다 (그림 2).
다음 예는 새 모델이 검색 품질에서 어떻게 더 잘 작동하는지 보여줍니다.
개발자 프롬프트 :“어떤 메소드가 찾기 위해 호출됩니다 단일 네임 스페이스 프로젝트 내에서 이름으로?”
Coplot Embedding Model을 사용하여 검색된 최상위 코드 스 니펫 FindOne 함수 (아래에서 굵게 표시됨)를 포함합니다:
class Namespace extends K8Object {
/*...*/
static findOne(params = {}, options = {}) {
return Model.findOne(params, options).then((namespace) => {
console.log(namespace);
if (namespace) {
return new Namespace(namespace).setResourceVersion();
}
});
}
/*...*/
}이전 모델을 사용하여 검색 한 최상위 코드 스 니펫에는 찾기 함수 (아래 굵게 표시됨)가 포함되어 있으며, 이는 잘못되었지만 Findone 함수와 의미 적으로 유사합니다.:
class Namespace extends K8Object {
/*...*/
static find(params = {}, options = {}) {
return Model.find(params, options).then((namespaces) => {
if (namespaces) {
return Promise.all(
namespaces.map((namespace) =>
new Namespace(namespace).setResourceVersion()
)
);
}
});
}
/*...*/
}Coplot Impedding 모델은 프롬프트 및 지침에 대한 개선 된 응답을 제공합니다. 또한 다소 관련성이 높은 검색 결과와 관련성이 높은 검색 결과를 더 잘 구별 할 수 있습니다.
개발자에게 혜택을주는 다른 시나리오는 다음과 같습니다.
- 큰 모노 로포에서 테스트 기능을 검색합니다
- 여러 파일에 헬퍼 메소드를 찾는 방법을 찾습니다
- 디버깅 코드 : “이 오류 문자열이 처리되는 위치를 보여주세요”
우리가 훈련 한 방법
우리의 목표는 예산 내에서 대기 시간과 메모리를 유지하면서 실제 개발자 워크로드에 대한 검색 품질을 최적화하는 것이 었습니다.
우리는 검색 품질을 사용하여 최적화했습니다 대조적 인 학습 ~와 함께 불신 손실 그리고 Matryoshka 대표 학습 – 임베딩이 거의 동일한 스 니펫을 구별하는 데 도움이되는 접근 방식은 유연성을 위해 다수의 임베딩 크기를 지원합니다.
주요 성분은 훈련이었습니다 단단한 부정: 올바르게 보이지만 그렇지 않은 코드 예제. 코드 검색의 대부분의 실패는 이러한 “가까운 미스”에서 비롯되므로 모델을 “거의 오른쪽”과 분리하도록 가르치는 것은 가장 큰 품질의 이익을 얻었습니다. 우리는 크고 다양한 Corpora (Public Github 및 Microsoft/Github 내부 리포지토리)에서 열심히 부정적인 채굴을했으며 LLM을 사용하여 미스 근처에서 까다로운 표면을 사용했습니다. 이를 통해 바로 가기 학습을 줄이고 일반화를 향상시키는 데 도움이되었습니다.
다음 예는 Hard Negatives의 대조적 학습이 어떻게 관련 코드와 거의 관련 코드 샘플을 구별하도록 모델을 훈련시키는지를 보여줍니다. 스톱 워드 테이블이 어떻게 채워지는지 묻는 쿼리의 경우 가장 관련성이 높은 코드 샘플은 파일에서 중지 단어 테이블을로드하는 함수를 보여줍니다. 단어를 테이블에로드하거나 파일에서 중지 단어를 읽는 기능은 쿼리에 응답하지 않는 하드 네거티브로 사용됩니다. (다음 예제의 쿼리는 다음과 같습니다 “중지 단어 테이블은 어떻게 채워 집니까?”.))

교육 데이터의 상위 5 개 프로그래밍 언어에는 다음이 포함되었습니다.
| 언어 | 데이터 믹스 비율 |
|---|---|
| 파이썬 | 36.7% |
| 자바 | 19.0% |
| C ++ | 13.8% |
| JavaScript/TypeScript | 8.9% |
| 기음# | 4.6% |
| 다른 언어 | 17.0% |
평가 스위트
코드 검색의 여러 측면을 다루기 위해 단일 테스트가 아닌 멀티 벤치 마크 평가를 사용합니다. 여기에는 다음이 포함됩니다.
- 자연 언어 (NL) 코드: 관련 기능/스 니펫으로 NL 쿼리에 응답합니다.
- NL에 코드: 코드의 자연어 요약.
- 코드로 코드: 유사한 기능 검색 (Refactored 또는 Transrated Code).
- 코드 문제: 문제 설명을 제안 된 코드 수정으로 전환합니다.
다음은 무엇입니까
새로운 Copilot 임베딩 모델은 AI 코딩 어시스턴트가 더 똑똑 할뿐만 아니라 일상적인 개발에 더 신뢰할 수있는 한 단계입니다. 앞으로 우리는 다음과 같습니다.
- 교육 및 평가 데이터를 더 많은 언어 및 리포지토리로 확장합니다.
- 더 나은 품질을 위해 하드 네거티브 마이닝 파이프 라인을 정제합니다.
- 효율성을 사용하여 더 크고 더 정확한 모델을 배포합니다.
개선 된 에이전트 검색 경험을 시도하고 싶습니까?
Code>에서 Github Copilot을 사용해보십시오
감사의 말
Github 및 Microsoft의 엔지니어와 연구원들에게 교육 파이프 라인, 평가 스위트 및 서빙 스택을 구축 한 Github Copilot 제품 및 엔지니어링 팀에게 부드러운 롤아웃을 위해 감사합니다.
작성자가 작성했습니다













, 테스트 및 검토됨")
Post Comment